


A fundamental concept in data that can easily be taken for granted is granularity. Granularity refers to the combination of data fields/columns that makes each individual record/row unique.
Imagine one day you’ve decided to take a break from your data and walk on a beach. The beachside is massive; sand is the only thing you can see. You’d like to see the beach in more detail - so instead of looking at the landscape, you lean down, gather a handful of the sand and watch each slightly different crystal pour through your fingers. You've come to realize you can't break this view down any further. Each individual, unique grain of sand is the highest level of detail available. That is granularity. Granularity describes the combination of fields required for every row in a dataset to be unique.
Why is it important for each row to be unique?
In the majority of cases, there are best practices for the structure of a dataset. These practices exist to make sure that the data can be relatively clean, consistent, and accurate. A few of these rules include:
- One Data Field for each category or measure (ex: Sales and Profits should be different fields/columns).
- One Data type in each field/column (don’t mix numbers and text values in the same field/column).
- Only a single type of date column, when possible (No separate MM/DD/YYYY [12/03/2025] and _ of Month [3rd of Month] fields).
- There is a way for your data to record different date values in connected data sets. But that’s for a separate blog introducing databases!
- One row should be a unique record containing all the values in each data field possible.
The fourth rule is one reason why understanding granularity, or what makes each record unique, is so important.
On a higher level, once you move towards doing analysis of your dataset, if you misunderstand the granularity, you might accidentally skew results or produce inaccurate analysis. Understanding the data structure is one of the most important steps in data preparation and analysis.
How do you find granularity?
In some cases, it's as simple as identifying a single field.
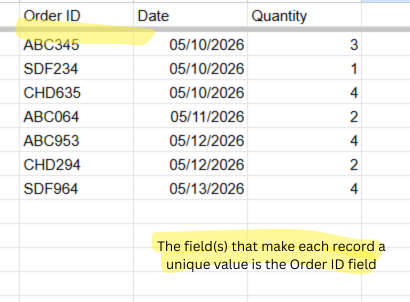
However, in other cases, granularity will be based on several fields.
We’ll continue to work with our earlier Superstore dataset to flesh this concept out. Superstore is a fictitious dataset showing a company’s retail sales - please feel free to check it out yourself. Some of the fields I’ve included below are the Order ID, Order Date (and time), Customer ID, and Product ID fields. Let's run through the ID fields to see where the granularity lies.
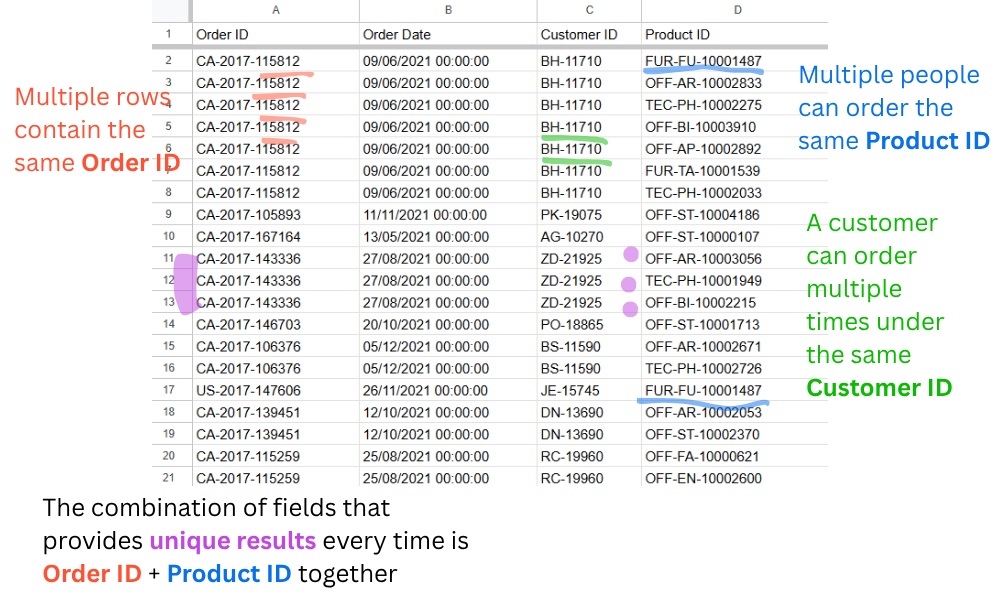
Starting with Order ID, it's clear right away that it repeats. The same order appears multiple times because each product within that order gets its own row (hint). Customer ID has the same problem: one customer can place many orders over time. Product ID is no different; multiple customers can order the same item.
The only fields that, when combined, give us a unique result every time are Order ID and Product ID.
This example shows that while it may be tempting to find an ID-field and assume it's the granularity of a dataset, it won’t always be the case. Granularity may seem like a small feature of data structure, but it's really the key to confirming your analysis has a strong foundation. The next time you start working with a dataset, its worth asking, “what makes every row unique?” Answer that question and you’ve already done a solid amount of work for your analysis.