


RegEx (short for Regular Expression) is THE standard when it comes to defining patterns in texts for matching, replacing, splitting, etc...
Just so you have an initial feel for it, here is a RegEx which matches all e-mail adresses in a text ending with .com (this won't work for any text, but most of them):

Very hard to understand at first sight, but you have to keep in mind that this expression defines pattern(s) for a computer. That is one of the reasons why I made this a two part series:
I. learn how a computer parses text with RegEx
II. learn to write your own RegEx
The RegEx:
Let's take an easy example: we have a list of strings and want to know in which of them the name "Bob" is included. To check this with a RegEx, we can just use the name itself:
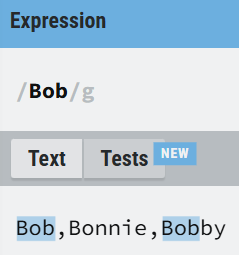
The State Machine
To understand the procedure of applying a RegEx, we will use a graph to show every step of it. I use a simplified version of the state machine called "DFA". Search for "dfa regex" online, if you are interested in the rigorously defined version of the machine.
The RegEx "Bob" can be equivalently represented by this state machine:

How it operates:
Start at State (1) and the first character of the string.
Go through the string character by character following these rules:
- If the next character matches the character on an arrow pointing away from the state we are in, we change the machine to that state.
- If we have no arrow to follow, we go back to (1) and continue.
- If we reach the final State ((4)) and cannot follow any arrow, we've found a match!
- Repeat until end of text
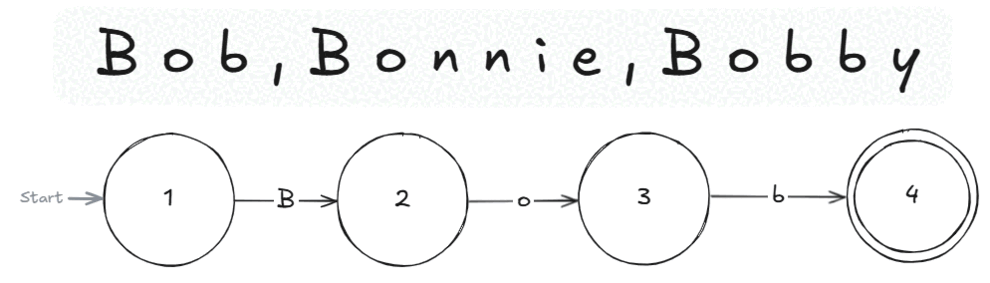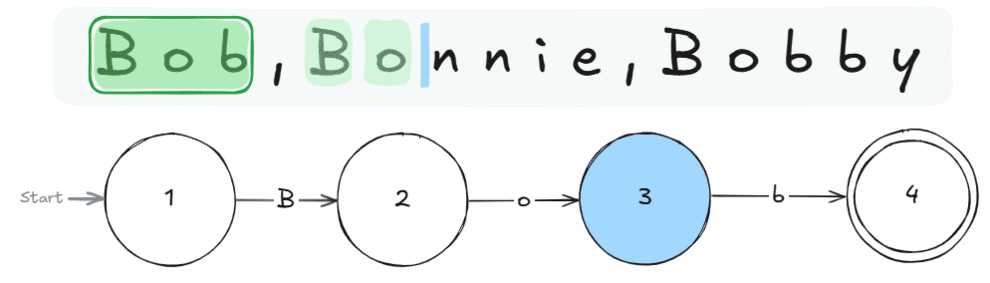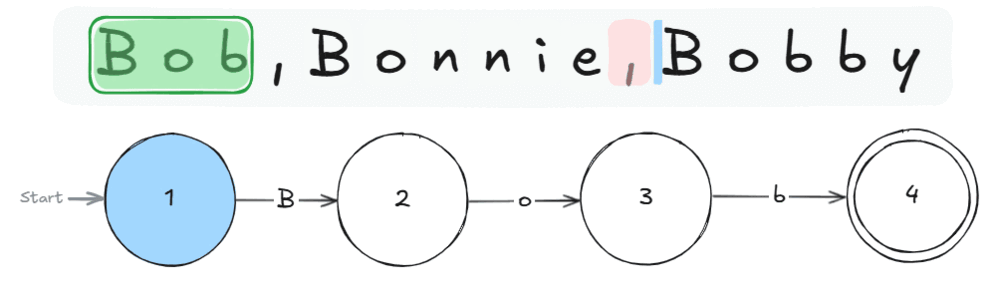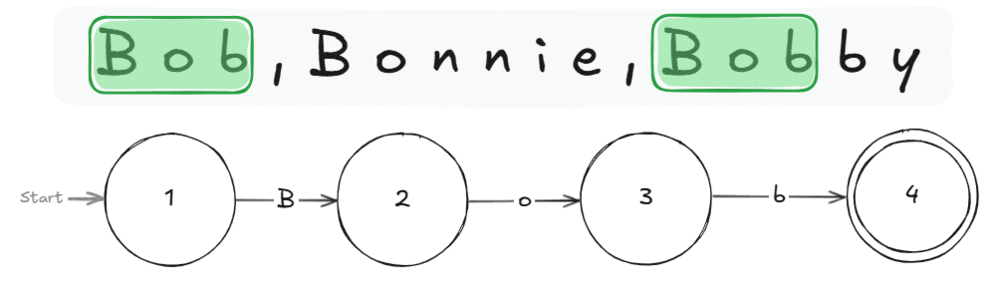
Knowledge gained: How a RegEx is applied to a given string of text.
Up Next: Special characters and how a RegEx is structured / used.