


During the first week of DSNY4 we began learning about data preparation with Tableau prep. This was a very intriguing topic for me because, for my first application viz, I initially wanted to work with climate change data. This data set needed some extensive cleaning before working with it on Tableau, so I tried to use python to clean it up. However, this proved to be quite difficult. I eventually gave up and used a different data set.
If I had known how to use Tableau prep, cleaning the climate change data would have been very easy. Tableau prep has quite a few powerful tools that help with data preparation. The most interesting functions that I have found so far are the automated tools for grouping data. These are used for fixing mistakes in the data set by grouping together data points that are written incorrectly.
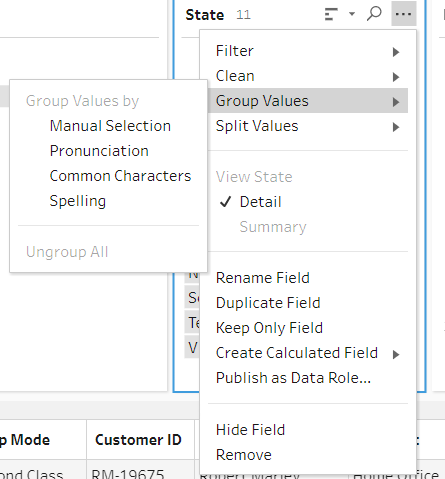
As shown above, there are four tools for grouping data:
- Manual Selection: This allows you to select which values to group together yourself by clicking on the value and then selecting which other values should belong with it.
- Pronunciation: Now we have some more powerful automated tools that can help clean data sets for us. Pronunciation will figure out which values sound similar and put them together. It does this through an algorithm that assigns each value a key based on how the word sounds. The words with the same key are then grouped together. There is also a slider that controls how sensitive the algorithm is. This algorithm is called Metaphone3 which is a phonetic encoding algorithm.
- Common Characters: This is another method that uses keys to help. The algorithm for common characters will remove all spaces, special characters, and capitalization. It then generates a key through the n-gram language model. Once again, values with the same key will be grouped together. However, there is no way to choose how sensitive this algorithm is.
- Spelling: The last method that we have will analyze each entry and calculate how similar they are to decide if they should be grouped together. It uses the Levenshtein distance algorithm to do this. This tool also has a slider which will alter the threshold for how similar the words need to be to have them grouped together.
These are some very powerful tools that will help save us a lot of time in the future!