


We’ve all been there. You pull a dataset into dbt, excited to start transforming it, only to realize there’s no ID field — no primary key, no unique identifier, nothing to reliably join or test on.
Without IDs, it’s hard to join tables, track changes, or even run some data tests properly. Luckily, dbt gives us a simple and consistent way to create custom ID fields, even if your source data doesn’t come with one.
Let’s go through how to do it cleanly using the generate_surrogate_key macro.
Why You Need an ID Field
A good ID field acts as a unique fingerprint for each record. It ensures you can:
- Join tables safely without duplicates or mismatched rows
- Run data quality tests that rely on unique identifiers
- Keep track of changes or updates when records refresh
- Avoid depending on fields that might change over time (like names or descriptions)
If your source tables don’t provide one, you’ll want to create your own.
Common Ways People Try to Create IDs
Before dbt, most people would create IDs in SQL using functions like CONCAT() or hashing functions like MD5().
For example: md5(concat(first_name, last_name, date_of_birth)) as customer_id
This approach works fine, but it gets messy quickly if you’re dealing with nulls, data type mismatches, or multiple joins. That’s where dbt and its built-in ecosystem really shine.
The dbt Way: Using generate_surrogate_key
Instead of writing your own hash logic from scratch, you can use a pre-built dbt macro that handles all the edge cases for you.
The generate_surrograte_key macro creates a unique key from one or more fields and takes care of things like nulls, concatenation, and hashing behind the scenes.
To use it, you’ll first need to install the dbt_utils package: Create a packages.yml file in your project’s root folder (if you don’t already have one) and add the following (OR the most up to date on the dbt utils page):
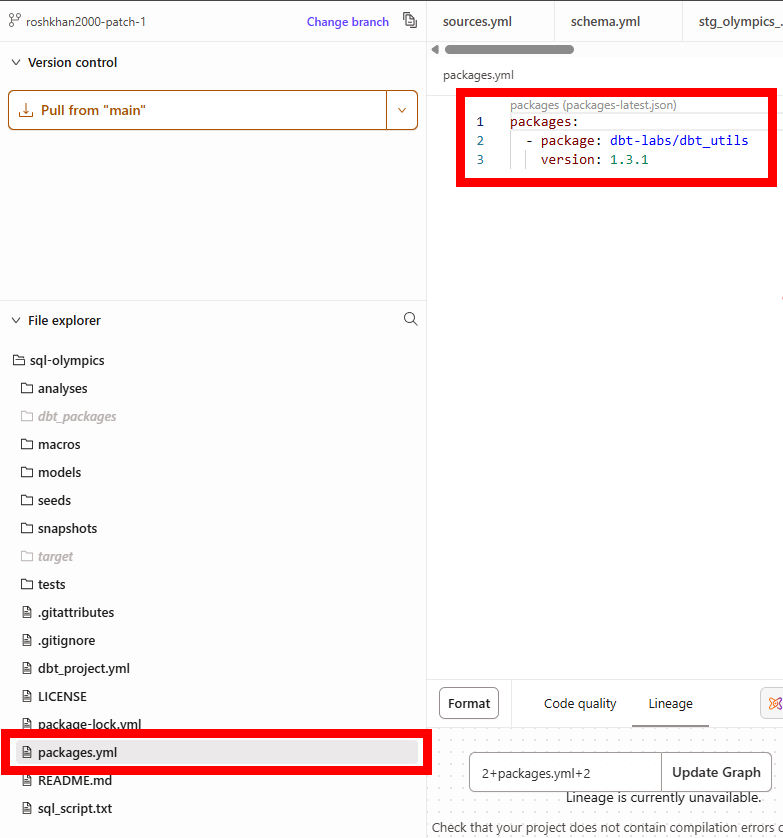
Then install it by running dbt deps
Once it’s installed, you can call the macro inside your SQL models like this:
{{ dbt_utils.generate_surrogate_key(['field_a', 'field_b', 'field_c']) }} as record_id
This will create a single hashed ID value that uniquely represents each combination of those fields.
Example: Creating a Custom Athlete ID
Let’s say you have a dataset of athlete stats with quite a few field but no unique identifier. You can create one using the macro like this:
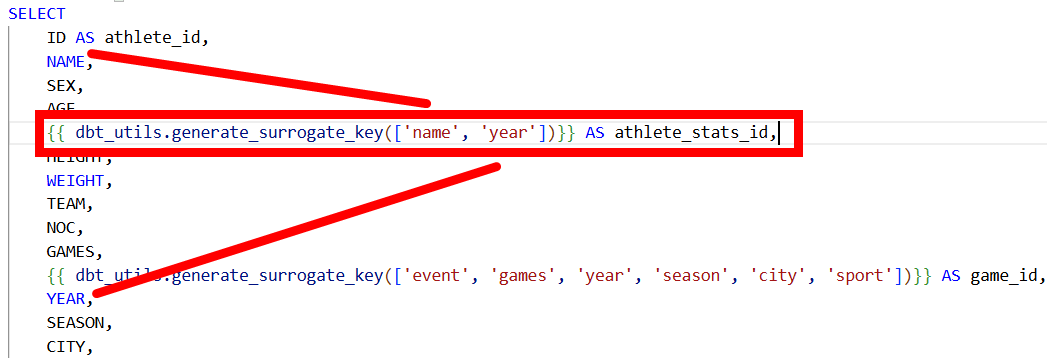
Now every record gets a unique athlete_stats_id that stays consistent as long as the combination of year and athlete_name stays the same.
Why Use generate_surrogate_key Instead of Plain SQL
You could technically build your own IDs with concat() and md5(), but there are some clear advantages to using the dbt macro:
- It automatically handles nulls and data type inconsistencies
- It uses a consistent hashing pattern across your entire project
- It’s easier to read, maintain, and reuse across multiple models
- It avoids subtle join issues that can happen when doing it manually
In other words, it standardizes something that most teams end up needing anyway.