


Another excellent package created by dbt Labs is codegen, which is designed to help you generate boilerplate dbt code automatically. One of its most useful macros is generate_model_yaml. This macro inspects an existing table or view in your warehouse and creates the corresponding YAML configuration for you — including columns and data types. Instead of manually typing column names into a schema file, you can run this macro and get a ready-to-use YAML block logged right in your command line.
In a previous speed tip, #macromanage Your Table Shape, we used another macro to pivot the Orders table in the Snowflake sample dataset (TPCH_SF1). That model produced a new table with twelve columns. Instead of manually typing out all twelve fields into a schema YAML file, we can save time by using the generate_model_yaml macro.
Before running this macro, ensure that your dbt project has been executed and that the model has been materialised as a table or view in your warehouse. Otherwise, the macro won’t have a relation to inspect.
Unlike other macros you might use inside a model with Jinja, generate_model_yaml is run directly from the command line. Here’s the syntax:
dbt run-operation generate_model_yaml --args '{"model_names": "name_of_model"]}'
The command will query your warehouse for the model’s metadata and log a complete YAML snippet to your terminal, including the columns block.
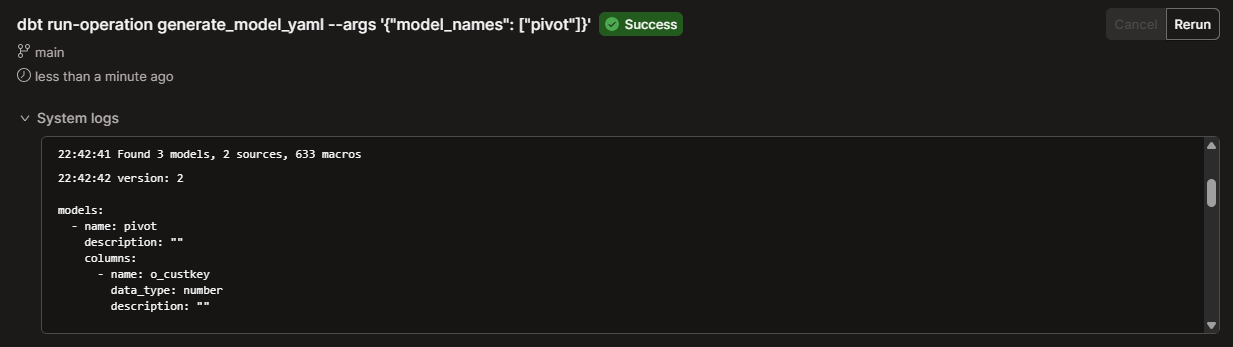
You can then copy and paste the output directly into your schema.yml file.
version: 2
models:
- name: pivot
description: ""
columns:-
name: o_custkey
data_type: number
description: "" -
name: year_of_order
data_type: number
description: "" -
name: sum_1-urgent
data_type: number
description: "" -
name: sum_2-high
data_type: number
description: "" -
name: sum_3-medium
data_type: number
description: "" -
name: sum_4-not specified
data_type: number
description: "" -
name: sum_5-low
data_type: number
description: "" -
name: cnt_1-urgent
data_type: number
description: "" -
name: cnt_2-high
data_type: number
description: "" -
name: cnt_3-medium
data_type: number
description: "" -
name: cnt_4-not specified
data_type: number
description: "" -
name: cnt_5-low
data_type: number
description: ""
-
This macro requires only one argument to run, but you can also include two optional ones to enrich the output.
1. model_names (required)
The model(s) you want to generate YAML for.
Must be passed as a list, even if it’s only one model.
2. upstream_descriptions (optional, default = False)
If set to true, the macro will inherit column descriptions from upstream models and sources when column names match.
Useful if you’ve already documented your raw or staging layers and want those descriptions to carry forward.
3. include_data_types (optional, default = True)
If true, data types will be included alongside the column names in the YAML.
If false, only column names (and any descriptions) will be shown.
The generate_model_yaml macro gets you 80% of the way there. The last 20% — adding meaningful descriptions — is up to you. This step may seem small, but it’s what makes your models discoverable, maintainable, and trustworthy for the next analyst who picks up your project.
If you would like to read more about how this macro was originally created, visit the GitHub page using this link.