


Regular Expression (RegEx) is very helpful when I need to clean or prepare the data. We use RegEx to match the input text based on a sequence of characters. In this blog, I am going to talk about:
1/ The qualifiers and the quantifiers in RegEx
2/ Output Methods in RegEx tools
3/ RegEx functions in Alteryx and tools used RegEx functions (Part 2)
The Qualifiers and the Quantifiers in RegEx
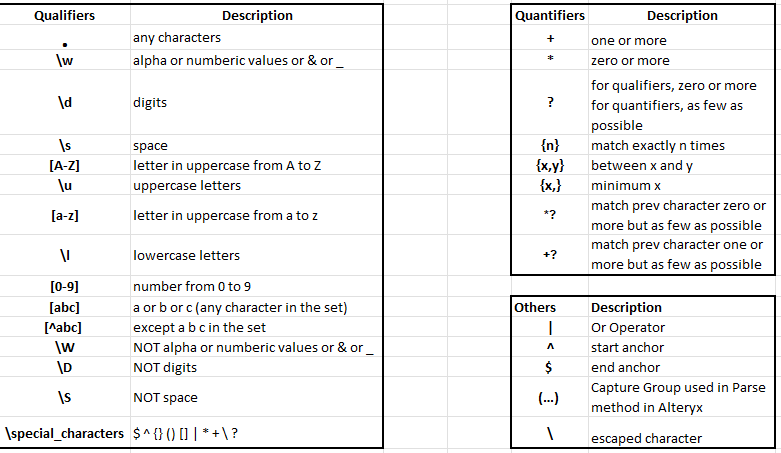
In RegEx, to check if the input text is matched or not, users will use the pattern in a sequence of characters. There are 3 groups to show the characters to express the pattern: Qualifiers, Quantifiers, and other characters (Image 1).
For example: I have a string: abcd2023/09/27DataSchool. I would like to extract the date in that string text.
So I will do Parse with the expression: .+(\d+\/\d+\/\d+).+
Explanation:
.+ is for any one or more characters before the group that I want to get
(\d+\/\d+\/\d+) is the group that I want to extract from the string text. Inside the group, it should include one or more digits then a character "/" and one or more digits for the month; then, a "/" character, and finally the day with one or more digits.
.+ is for one or more characters after the group
Output Method in RegEx tool in Alteryx
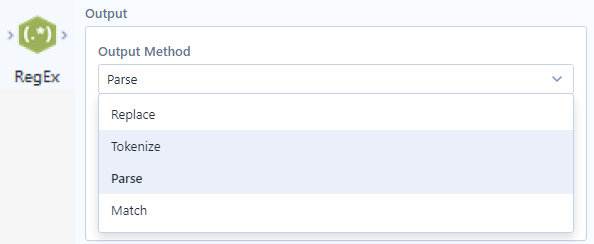
In the Parse palette, I can drag the RegEx tool to connect with other tools that I am using in the workflow. There are 4 main Output Methods (Replace, Tokenize, Parse, Match) in the RegEx tool in Alteryx (Image 2).
1/ Replace
The Replace method replaces the value that matches the Regular expression by a replace text.
For example, I have an input data: "Hello World, today is the 1 day at school.". Now, I would like to replace the number 1 in that sentence with the text "first".
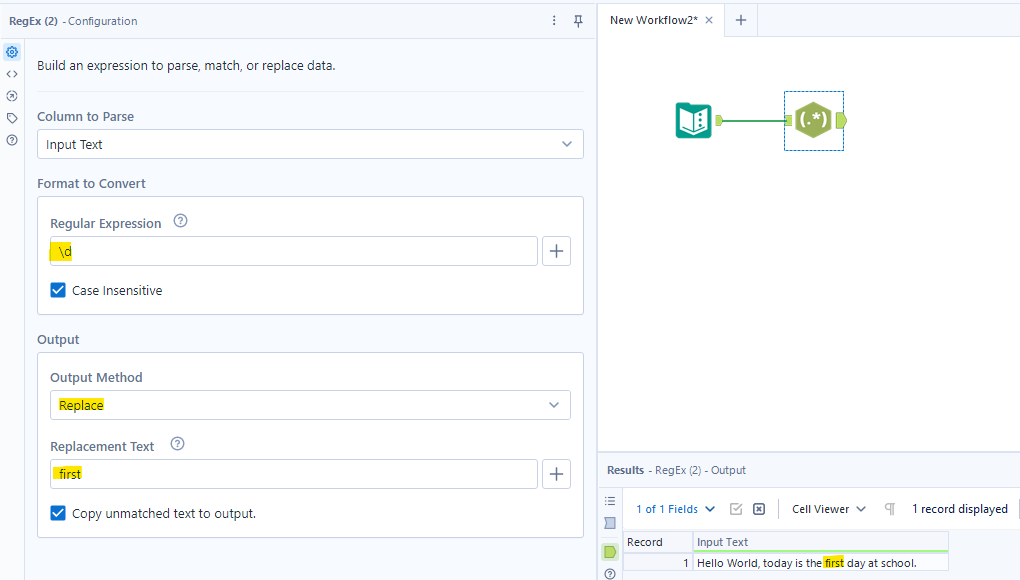
I know that 1 is a digit. In the Regular Expression box in the Configuration window, I type \d which represents 1 digit in the sentence. In the Output method, I choose Replace. In the Replacement Text, I type first for the text that I would like to replace at that digit place. Then, click run. In the result window, it will change the digit into the "first" word. (Image 3)
2/ Tokenize
The tokenize method allows the user to specify a regular expression and split the input data values into rows or columns that match that regular expression.
For example, I have a sentence: "Hello World, today is the first day at school. I have a notebook, a pen, a pencil in my backpack. I met many friends.". Now, I would like to split each small sentence into rows.
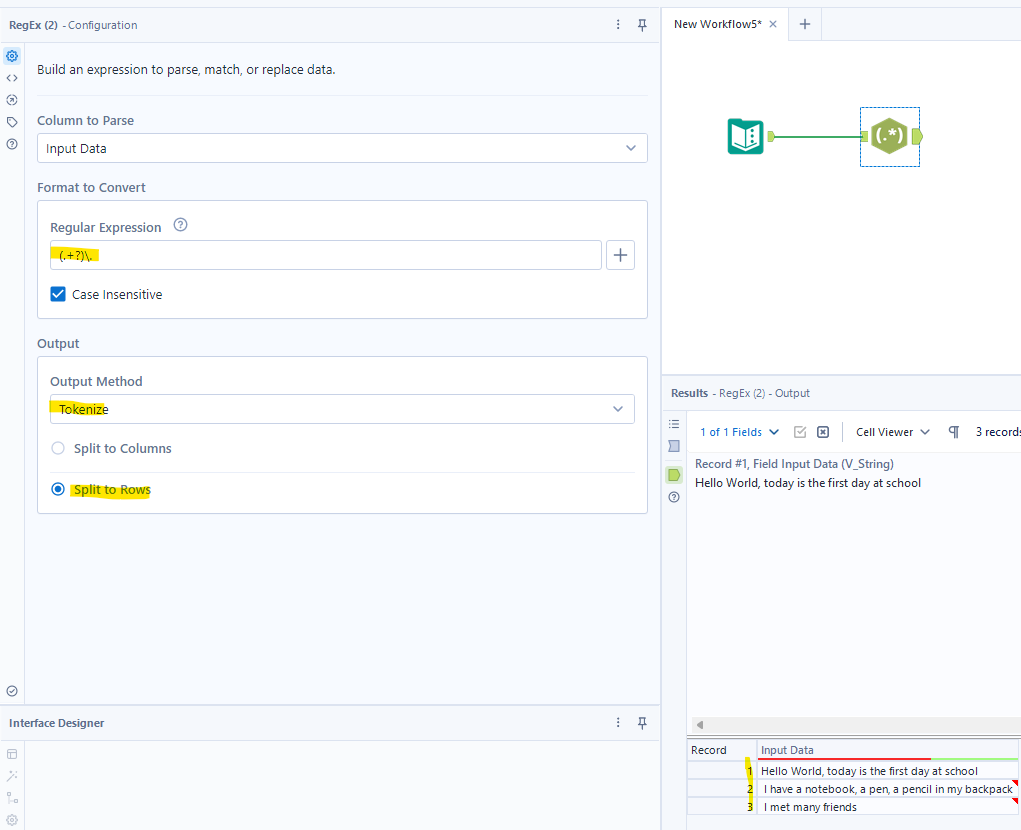
Each sentence is separated by a period. So, I will split the input data in each row with a delimiter as a dot. In the Regular Expression box, I use (.+?)\. It means returning all characters before the dot. Next, I choose Tokenize in the Output Method. Then, splitting into new rows if there is a dot. In the result window, I got 3 rows for 3 sentences as I wanted. However, there is a space before the sentences 2 and 3. I can clean it by using a cleaning tool.
3/ Parse
The Parse method allows the user to return the values that match the regular expression in the parentheses.
For example: I would like to get the text between a pair of <p> tags:<p> Hello World, today is my first day at The Data School New York </p>
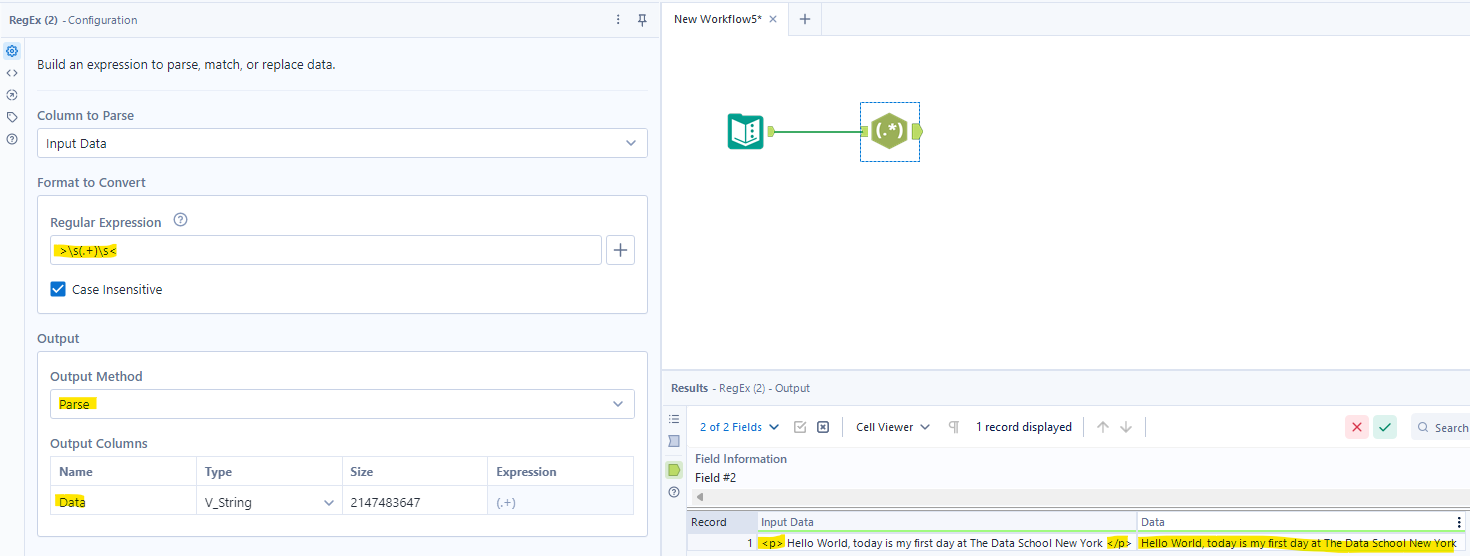
I recognize that the text is between a pair of tags, and there is a space before and at the end of the text. Therefore, in the Regular Expression box, I type >\s(.+)\s<. It means returning all characters between spaces outside with greater than (>) and less than (<) marks. It only returns values that match the regular expression in the parentheses.
4/ Match
The Match method allows the user to check if the input data satisfies the condition or the format that the user wants. If it satisfies the condition, then return True; otherwise, return false.
For example: I have an input data: ID HoangLe Email lenguyen@abcxyz.com. I would like to check if that input data included the email or not. If that input includes the email, then return True; otherwise, return False.
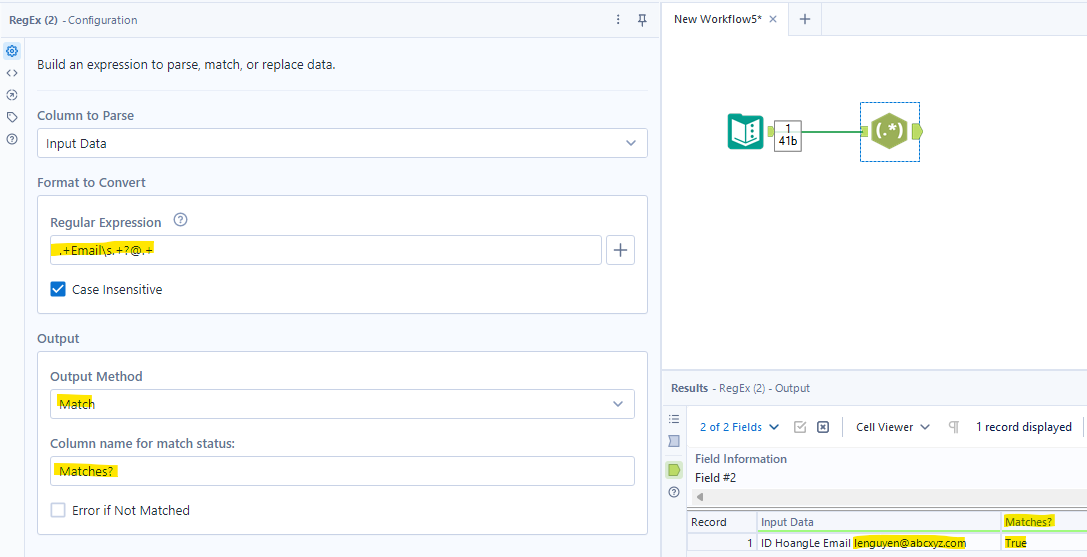
I recognize the email is after the "Email" word with a space, and the email has a "@" symbol. In the Regular Expression box, I use .+Email\s.+?@.+. It means the input data should have value as some characters before the "Email" word and a space. Then, there are some characters before a "@" symbol and some characters after that symbol. If the input data satisfies that expression, it will return True. In the Output Method, I choose Match, and the column name is "Matches?". In this case, the input data satisfies my expression, so it returns True in the "Matches?" column.
In the first part of Regular Expression (RegEx) in Alteryx, I introduced the definition of Regular Expression, the qualifiers and quantifiers of RegEx. Then, I also show how to use the RegEx tool in Alteryx to return the values that the user wants with 4 different types of output methods (Replace, Tokenize, Parse, Match).
In the second part of Regular Expression in Alteryx, I will summarize some RegEx functions in Alteryx and tools used in RegEx functions. It would be very helpful if the data is complicated with text, number, and date type.
I hope the blog is helpful to you. If there are any parts that you have questions about or are not clear, feel free to contact me on LinkedIn or Email.
See you again in the second part!