


Extracting data is one of my favorite topics. I have some blogs about extracting data from a web page, API. If you have not read it yet, you can read Web-scraping in Alteryx here, API in Alteryx part 1 and part 2. Sometimes, we can easily download data from a CSV file, or Excel file, or extract data from a web page or API. However, many datasets are not from those formats; it could be a PDF file or an image file and you want to extract data from those formats. One important thing is when you extract data from a web page is respecting the data privacy of the web page or the data owner.
How can we extract data from a PDF file in Alteryx?
That is the question I usually ask myself. In this blog, I am going to share step-by-step how I extracted data from a PDF file in Alteryx. I will walk through:
1/ Set up the environment
2/ Input the PDF file and fix some common errors
3/ Storing the list in the Pandas DataFrame
4/ Output data from the Python tool in Alteryx
Are you ready? Let's get started!
1/ Set up the environment
Note that, the instruction can work successfully depending on the PDF encoding format. In this part, I will note some errors that happened to me when I was working on extracting data from a PDF file and I will give solutions on how to fix them. To extract the data from a PDF file with Python in Alteryx, I use the Tabula library. You can read the Tabula Documentation here.
- Libraries in Alteryx
Some libraries have been included for the Python tool in Alteryx:
- ayx
- jupyter
- matplotlib
- numpy
- pandas
- requests
- scikit-learn
- scipy
- six
- SQLAlchemy
- statsmodels
You can read more information about those libraries in Alteryx here. We use the Tabula library in this blog, but it is not included in the Python tool. Therefore, I need to install the Tabula library later.
- Open Alteryx
I got an error when I installed the Tabular library. When you install a library not included in the Python package in Alteryx, you need permission from the Administrator. So make sure that you are running Alteryx as an Administrator by right-clicking on Alteryx Designer and choosing Run as Administrator (Image 1).
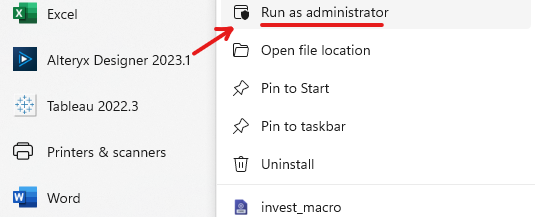
- Install Tabula package
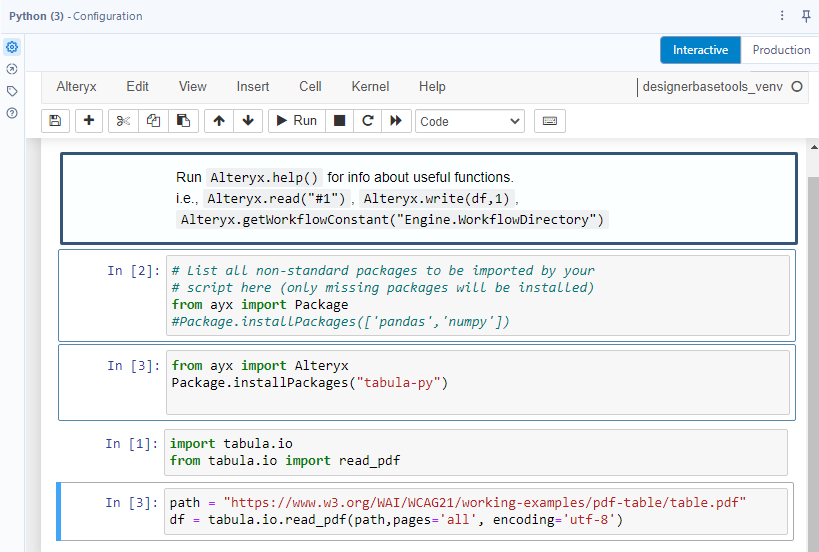
When Alteryx Designer opens, you can go to the Developer palette and drag the Python tool into the canvas or you can search it in the search box. Then, clicking on the Python tool, the configuration window will open on the left (Image 2).
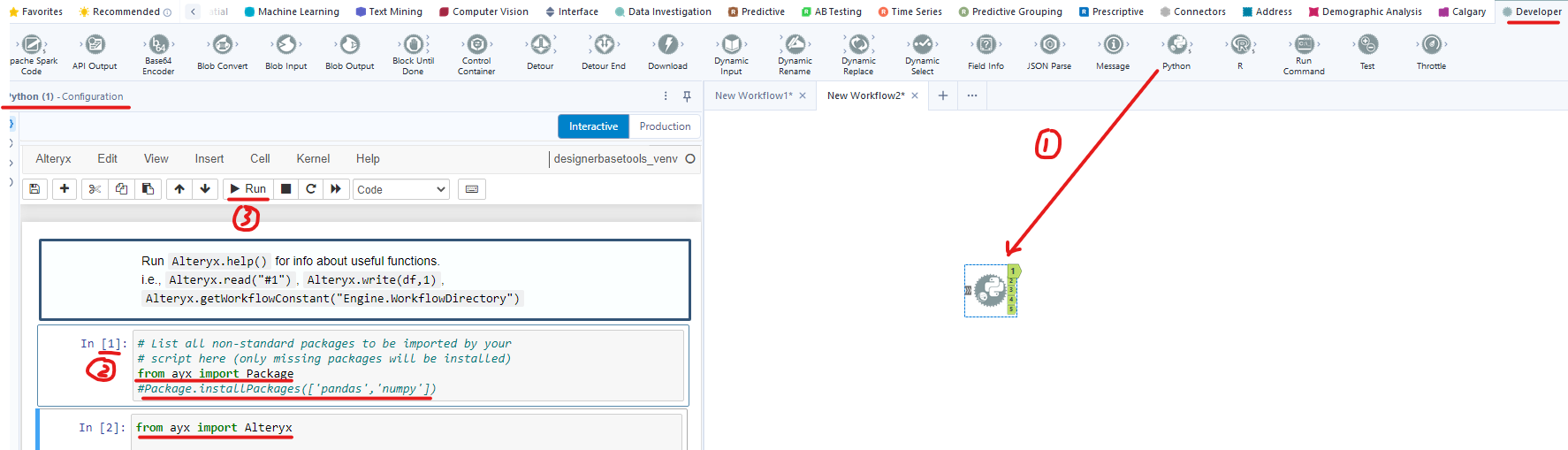
In the Configuration window, Alteryx has an instruction on how to install the package. Alteryx automatically imports the library that I listed above. However, if you want to use a package that has not been listed in the list above, you need to import it with some code lines.
from ayx import Package
Package.installPackages( ['pandas','numpy'])
From the 2 coding lines above, Alteryx shows how to import the pandas and numpy library with the syntax: Package.installPackages( [list of libraries in the single quotation mark and separated by commas]). Now, I want to import the Tabula package, so I will type:
Package.installPackages('tabula-py')
Then, hold Ctrl and Enter or Click on the Run button above to run the cell. It will run without any errors (Image 3).
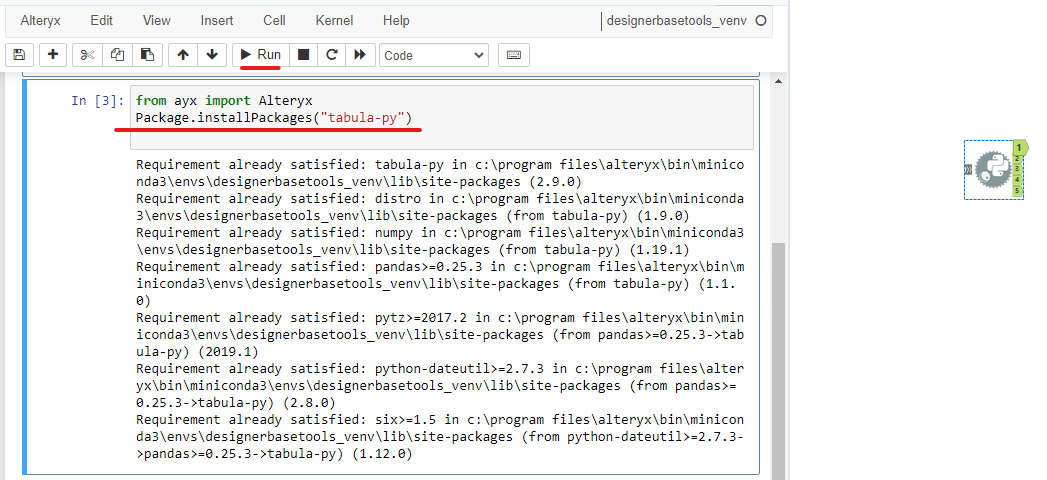
After installing the package, I need to import the function read_pdf from the Tabula package to read the PDF file. By clicking on the "+" button or holding Shift and Enter to create a new cell, I import the function by writing (Image 4):
import tabula.io
from tabula.io import read_pdf
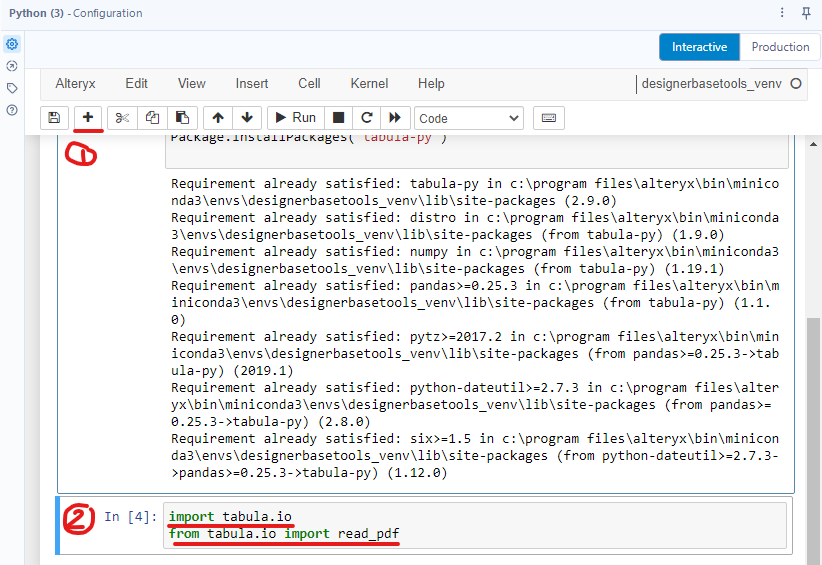
Then, hold Ctrl + Enter to run the cell. If it runs without showing any errors, it would be fine.
2/ Input the PDF file and fix some common errors
I had many troubles in this step. I will show some errors that I met and show how to fix them. In this step, I create a new cell. I will use a remote PDF file as an example. This is the link to the PDF file: https://www.w3.org/WAI/WCAG21/working-examples/pdf-table/table.pdf (Image 5)
In the new cell, I will type:
path= "https://www.w3.org/WAI/WCAG21/working-examples/pdf-table/table.pdf"
df = tabula.io.read_pdf(path, pages='all', encoding='utf-8')
I use the path variable to store my URL; remember to put the URL path in quotation marks. In the next line, I create a variable called df which means dataframe in short. To call the read_pdf function, I need to put the library before the function. The syntax of the read_pdf function is:
read_pdf( [directory of the PDF file], pages='[all or page number]' , encoding='utf-8')
The first parameter in the read_pdf function is the directory of the PDF file, then the page in the PDF file you want to extract data. If you want to get all pages, put 'all' in the quotation mark; otherwise, put the page number inside the quotation mark. The last parameter is the encoding format; I put utf-8 which stands for Unicode Transformation Format - 8 bits (optional; by default, read_pdf function uses utf-8 format but you can switch to another encoding format). Then run the cell (Image 6).
Some errors that I met:
1/ module 'tabula' has no attribute 'read_pdf'
Fix: Make sure you install the package "tabula-py" and import tabula.io. When you use the read_pdf function, remember to put tabula.io before calling the function.
2/ `java` command is not found from this Python process. Please ensure Java is installed and PATH is set for `Java`
Fix: Because the Tabula package is based on the Java platform, you need to install Java SDK on your computer. Then, you need to open the Advanced System Setting to edit the Java path. There is a video showing how to fix this issue: https://www.youtube.com/watch?v=Sbic3aMCwhY from the E Micro Tech channel. After that, you can run the cell again or restart Alteryx and run again.
3/ UnicodeDecodeError: 'utf8' codec can't decode byte 0xa5 in position 0
That error will appear when the read_pdf function cannot decode the text in the PDF file. Sometimes, there is a logo in the file that cannot decode to ASCII code or Binary code (0 and 1 bits).
Those are errors that I met when using the read_pdf function to extract the data from the PDF file. Many errors could happen; you can check errors and other parameters here. The df variable will return a list or a dictionary.
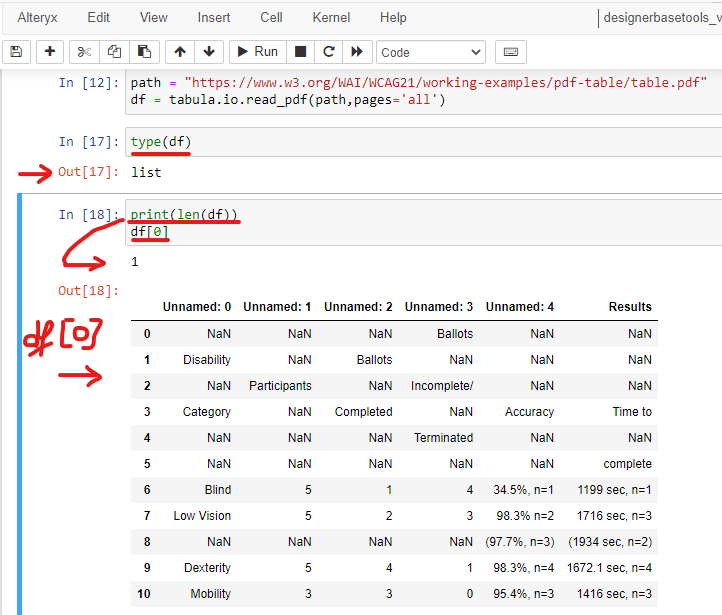
In the next step, I use print(len(df)) to output how many lists or dictionaries are in the df variable. I use type(df) to print out the data type of the df variable. That is a list. Then, I type print(len(df)) to print out how many lists are in the df variable. There is only 1 list in the df variable, so I use df[0] to print out the data frame (Image 7).
3/ Storing the list in the Pandas DataFrame
To output the data from the Python tool, it requires the data to be a Pandas data frame. Therefore, I need to store the element df[0] in a Pandas data frame. Pandas is already installed in the package as I mentioned in the list above, so I only need to import the pandas library now.
I created a new cell then type (Image 8):
import pandas as pd
data = pd.DataFrame(df[0])
data
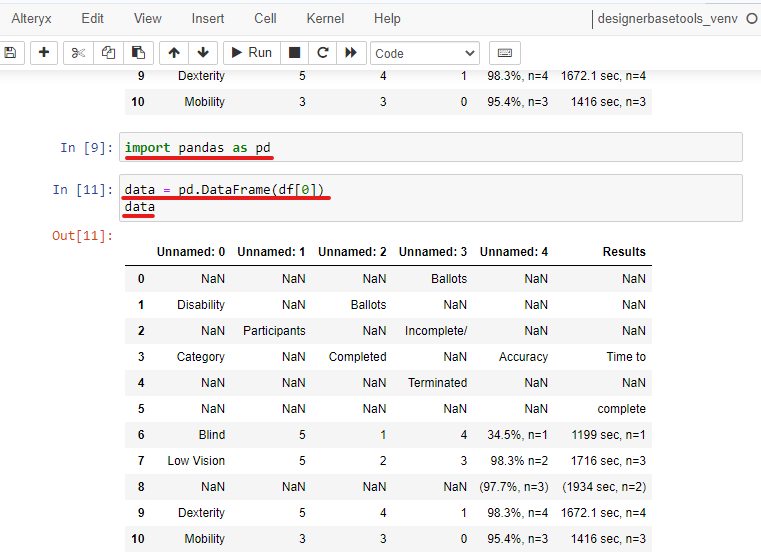
On the first line, I imported the Pandas library and called it pd for short. Then, I created a new variable called data. I use the DataFrame function to convert df[0] into a Pandas data frame; remember to call the pd library before using the function. Finally, I can print out the data to view (Image 8).
4/ Output data from the Python tool in Alteryx
From now on, you have 2 options. The first option, you clean and prepare the data directly in the Python tool with the Pandas library and then output the prepared data from the Python tool. The second option, you output the data from the Python tool. Then, you can use the Alteryx tool to clean and prepare data.
In this blog, I only share how to output data from the Python tool. In Pandas, I can use the head() function to output the number of rows from the top or tail() to output the number of rows from the bottom.
I created a new cell and created a new variable called output_data to store the last 5 rows from the data variable. So I type output_data = data.tail(5). Then I want to output from the first output anchor of the Python tool. I type Alteryx.write(output_data,1). (Image 9)
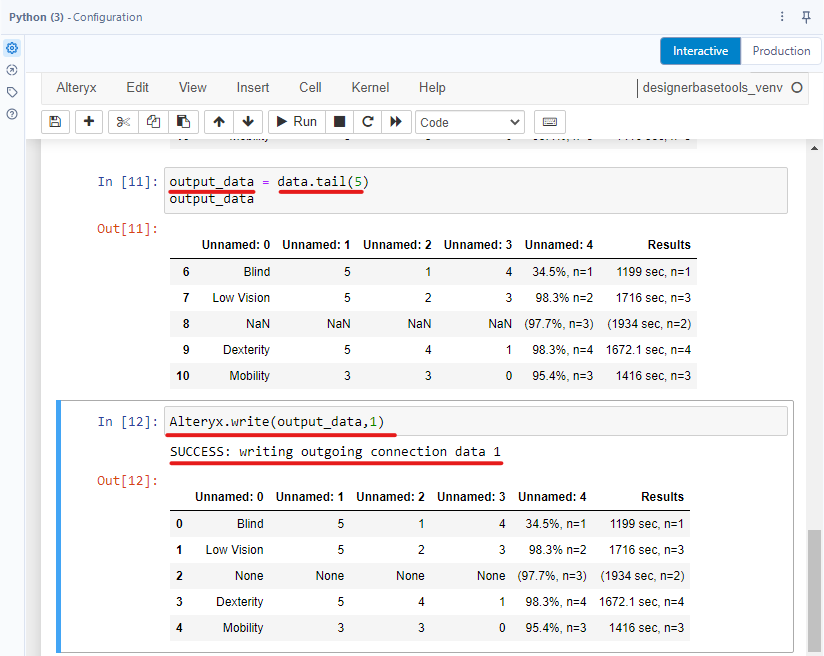
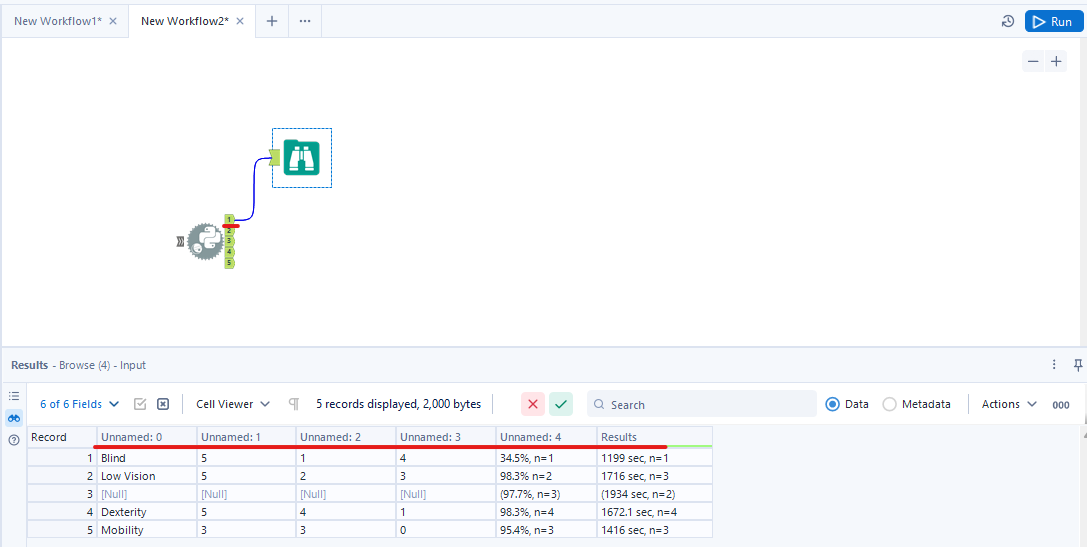
Run the cell. If you see the SUCCESS message, it means it works successfully. I connect the Browse tool to the first output anchor in the Python tool. Then run the workflow. The output data will appear in the Result window (Image 10).
This blog is long. Thank you for reading until now. In this blog, I introduce how to set up the environment, install the missing package, and import the library and function. Then, I input the PDF file and store the data in the Pandas library. At the end, I output the data from the Python tool. There are many errors during the process. If you have any more errors, feel free to contact me.
Thank you for reading. See you in the next blog!