Have you ever looked at a website and thought, how I would love to use their data. You could sit there with an excel spreadsheet writing/copying and pasting lines and lines of strings for hours to get a few hundred rows of data...or you could get the entire database in a matter of seconds using webscraping!
Before I teach you how to webscrape in Alteryx, BEWARE.
Webscraping is not always welcome. Some websites may flag you as a bot if you send too many requests at once and you may be IP banned from the website, so, especially when you are learning, please stick to websites built for learning webscraping.
Without further ado, let's get to webscraping!
The website we are going to use today to practise is https://books.toscrape.com/ . It is a fake bookstore built purely for webscraping practise, so you can have fun using it with no worries.
In order to understand webscraping, you first need to have a basic understanding of HTML. HTML is read by your internet browser (think google chrome) in order to layout the website in the way you see it. It is made up of multiple pairs of tags which a starting tag looks like this <tagname> and an ending tag looks like this </tagname>. Some tags have classes, one of the tags we'll be using today looks like this <p class="price_color">£51.77</p>. You can see that this pair of tags has a class 'price_color' and they contain the price of the book '£51.77'. The HTML is hierarchical, often starting with a header (containing the title of the website), then the body (often containing the information you may be looking for).
When webscraping you will constantly be checking the HTML to find the information you are looking for. In order to do this, you can right click the webpage, then click
- 'view page source'
This gives you all of the HTML as a massive document. This can be hard to find what you are looking for, but you are able to copy information here.
2. 'Inspect Element'
This appears as a panel on the side of your screen beside the webpage. Hovering your mouse over the tags, highlights what those tags show on the webpage as a blue rectangle. Great for trying to find a single piece of information, however you are unable to copy and paste the tags and information you are looking for.
Now that we understand HTML, we can now start webscraping!
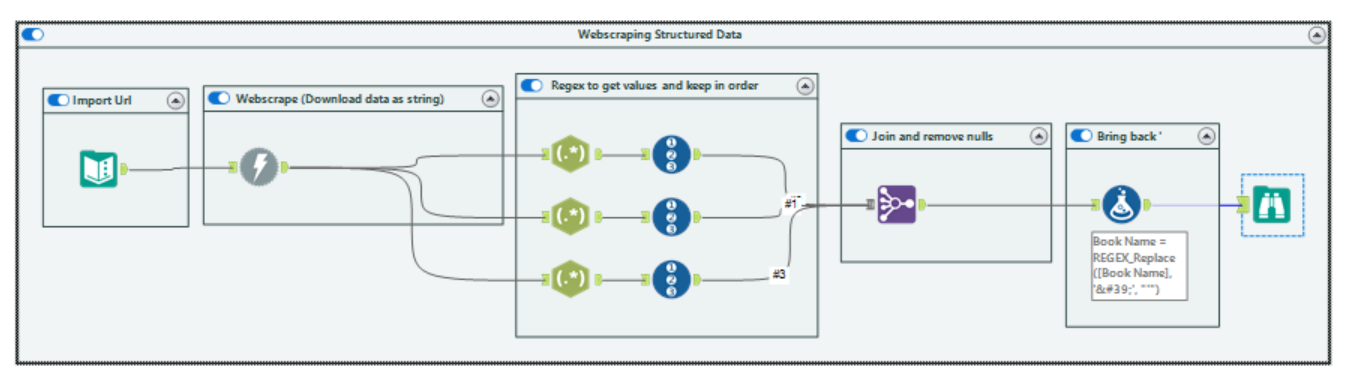
- First we need to input our websites URL. We do this using the 'text input' tool. Simply drag this onto your canvas and type your url into the left table, as you would an excel file.
2. Next, you want to download the URL, using the 'download' tool, in the developer tab.
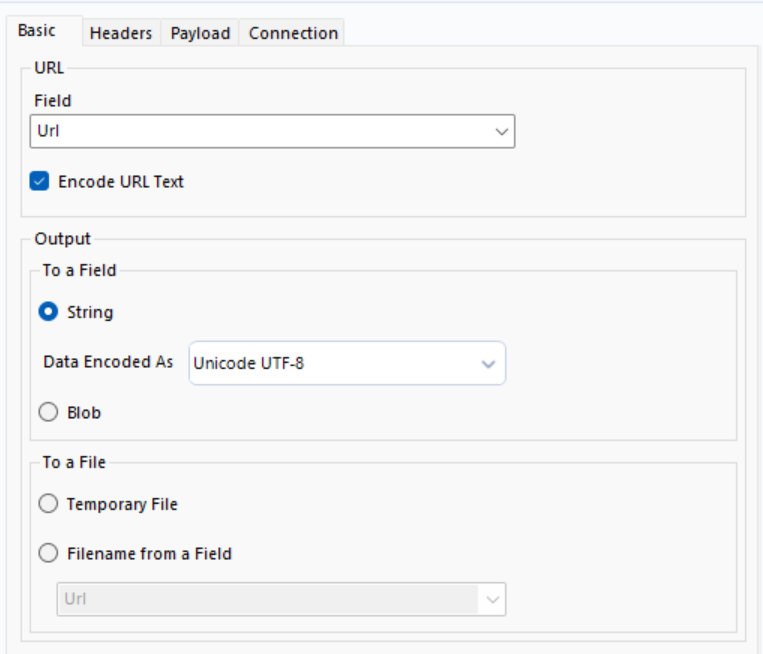

URL is simply your URL from the text input, and we want to import our HTML as a string. The Blob underneath stands for Binary Large Object and it is used to import image or media files, today we will only be looking at string/numeric data, so we will not make use of this.
Now, if you look back at the original HTML from the website, you may notice the string in the DownloadData column. It is the first line of the HTML, and this means that our HTML has downloaded correctly and is ready for use.
3. Now we want to get the data we need from this column, but first we have to understand what exactly we want. As this is a book store website, let us find the name of the book, its price and finally, its star rating.
First we have to use Inspect Element or View Page Source, to find what we are looking for in the HTML. By using either method, you should be able to find this:
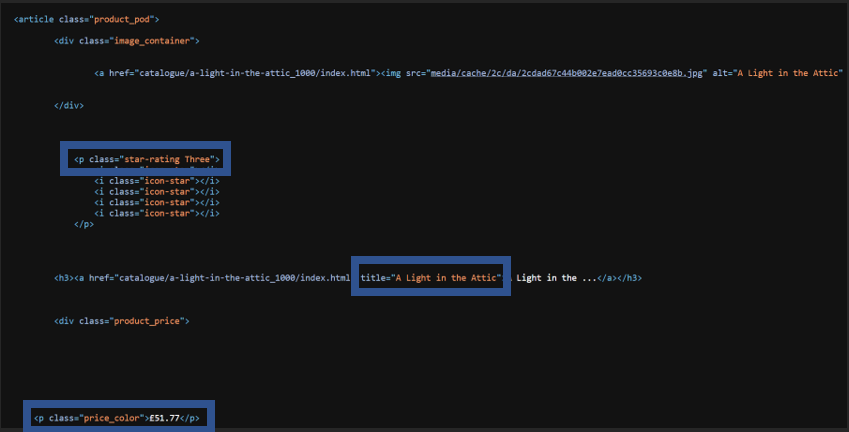
This is within the <article class="product_pod"> tag, which contains the information of a single book called A Light in the Attic. As I have highlighted for you, you can see the tags contains the star rating, book name, and price. This is what we want to find, and we will do this using RegEx. Let us start with the book name.
4. Drag the input tool onto your canvas.
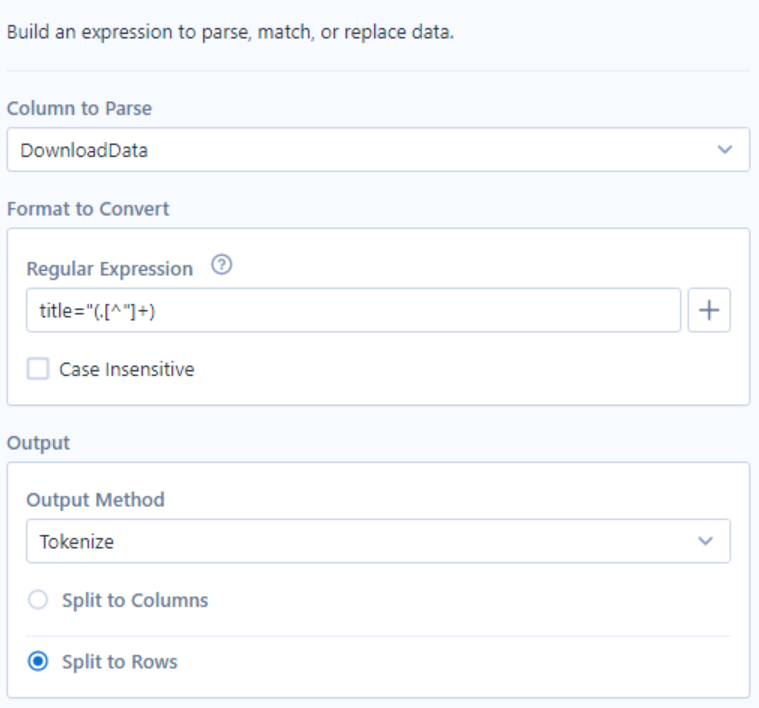
- DownloadData, holds the HTML as a string, so this is what we want to use RegEx to find our tags and hence our data.
- Format to convert is our regex. What I find useful, is to copy and paste the data into this text box...so start with
title="A Light in the Attic" => title="(A Light in the Attic)"
Here the brackets mean, we want the RegEx tool to take this section from anything in the string that starts with title=".
Now we need to tell it what is held inside, we can try
=> title="(.)" which means take any single value that is not a new line...but we do not want a single value.
=> title="(.+)" this takes any number of values that is not a new line...but this " is not a new line? So what if we have title="A Light in the Attic" More Information"?
=> title="(.[^"]+) this says, take anything any number of values that is not a new line or a ". Perfect.
Finally, we want to tokenize and split to rows, as we want to have each book as a single row, and tokenize is the RegEx version of split to columns in Alteryx.
5. Now to get the book's prices and star rating. Once again use the RegEx tool, but connect all 3 of these tools to the download tool. Use the same idea to get their regular expressions.
- Star Rating: <p class="star-rating (\w+)
- Price: <p class="price_color">£(\d+\.\d+)<\/p>
Note that I did not take the £ sign as this would force the price column into being a string value and we want price as a numeric value in order to use in the future.
Another note is that particularly in price, we had to escape the / as this is a special character in RegEx, meaning it has another meaning, and so in order to use it as a 'forward slash' as part of the text, we have to escape it using back slash.
6. Now we have all of our data, but in separate data sets. Luckily, the RegEx tool does not reorder data, so we can use the 'Record ID' tool, to give each row a unique number in our separate datasets. Now we can use the join tool to stick them together. Removing duplicate and useless columns, we should get exactly what we want.
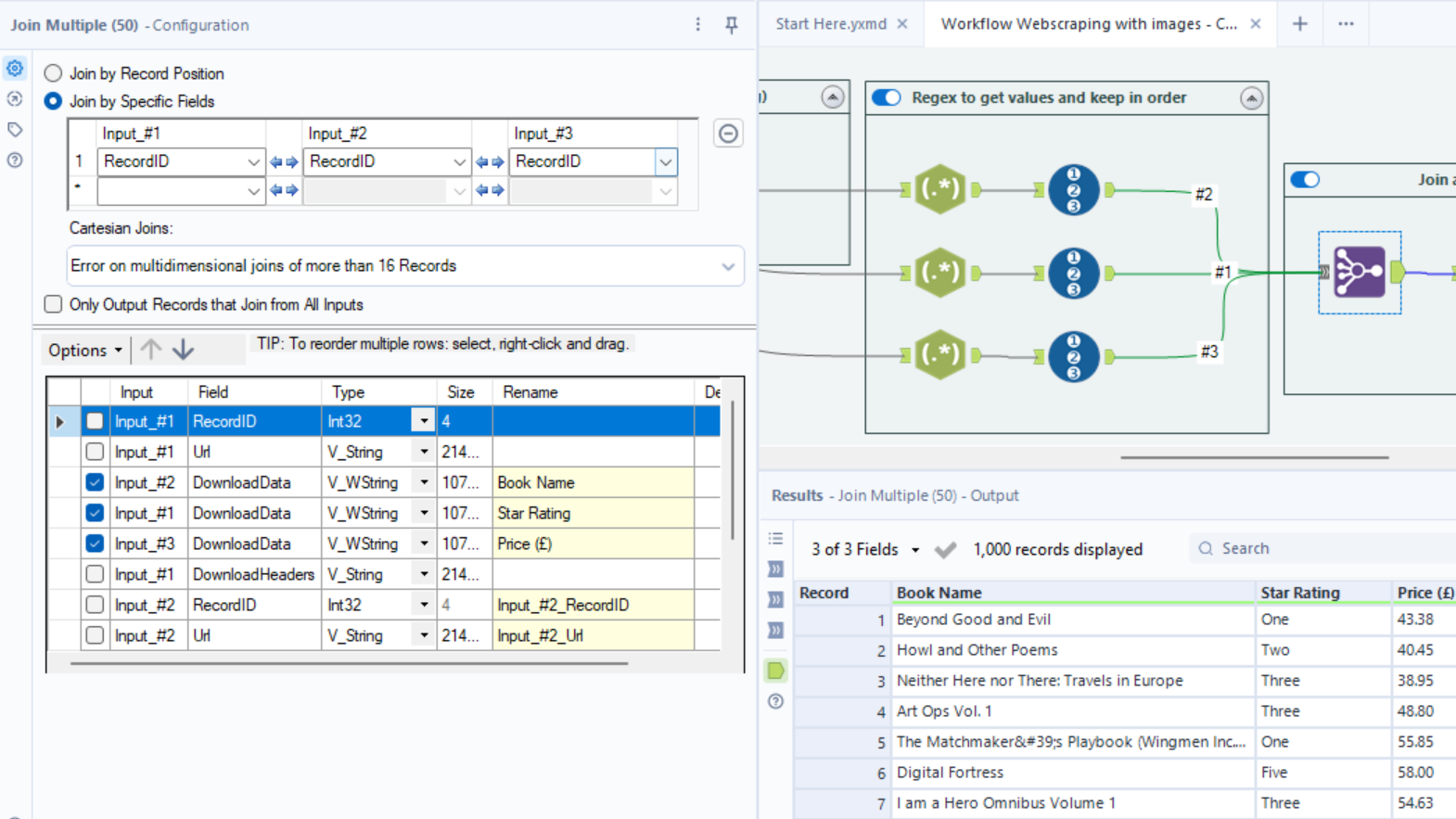
You can use the join tool to rename your columns. Make sure when renaming that the input_#x number, matches the number on the connection line.
Now when looking through your data you may notice something strange. If you look at record 5, you will see 'The Matchmaker's Playbook...'. Due to encoding rules for downloading URLs, certain 'unsafe' characters are transformed into a key, to make them safe to transfer. The apostrophe they used on this website is one of them. Luckily, we can use the formula tool with the replace function to bring the apostrophe back.
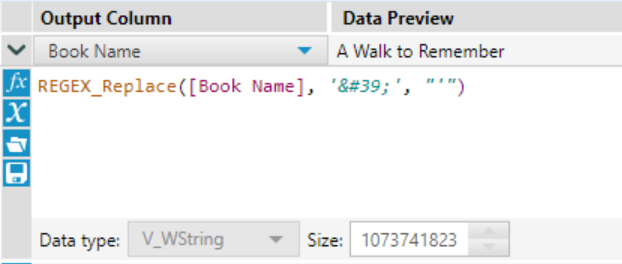
Now we should have a perfect dataset of books.
If you would like to see the entire workbook: