Web scraping is the process of extracting data from websites.
If a web scraping process is done correctly it has many business advantages:
It can help reduce costs - due to less time being spent on data extraction tasks. This is due to the process being automated once set up.
High quality data - when web scraping is done correctly and has formatting within it, you can have access to clean, high quality data that can be used more easily.
Accurate data - Web scraping is a more reliable way to collect data that human data collection.
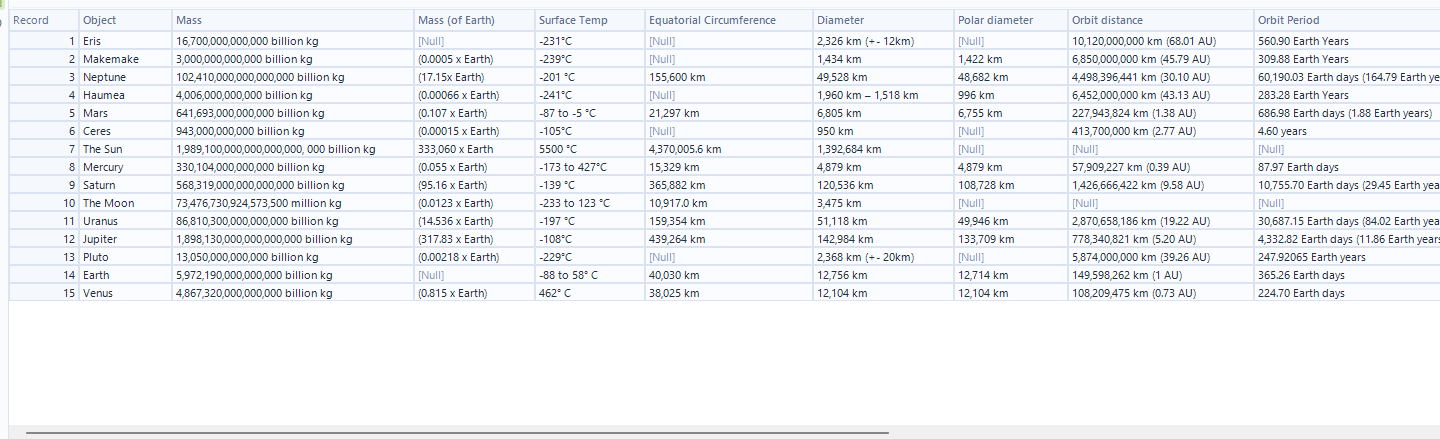
This blog will go over the process used to extract data from websites by web scraping using Alteryx. In this example, https://theplanets.org/solar-system/ is the site being extracted from. The profile data of the objects is the information that will be extracted and made into a table. As mentioned earlier, web scraping once set up is an automatic process, therefore should any of the information on the website change, so should the final table of data that is extracted when the workflow is run.
1) First locate the website URL and copy this into a text input tool on Alteryx
2) Next attached a download tool to the text input enduring the URL field is correct. The download tool will the download the data on the website in the form of a string.

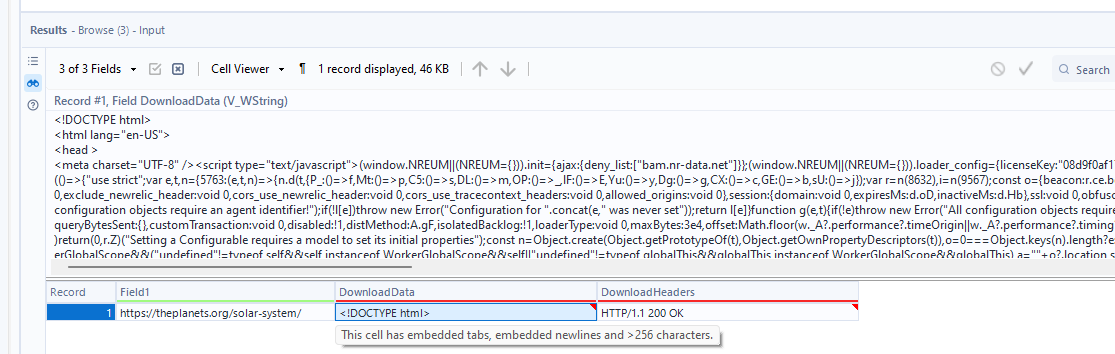
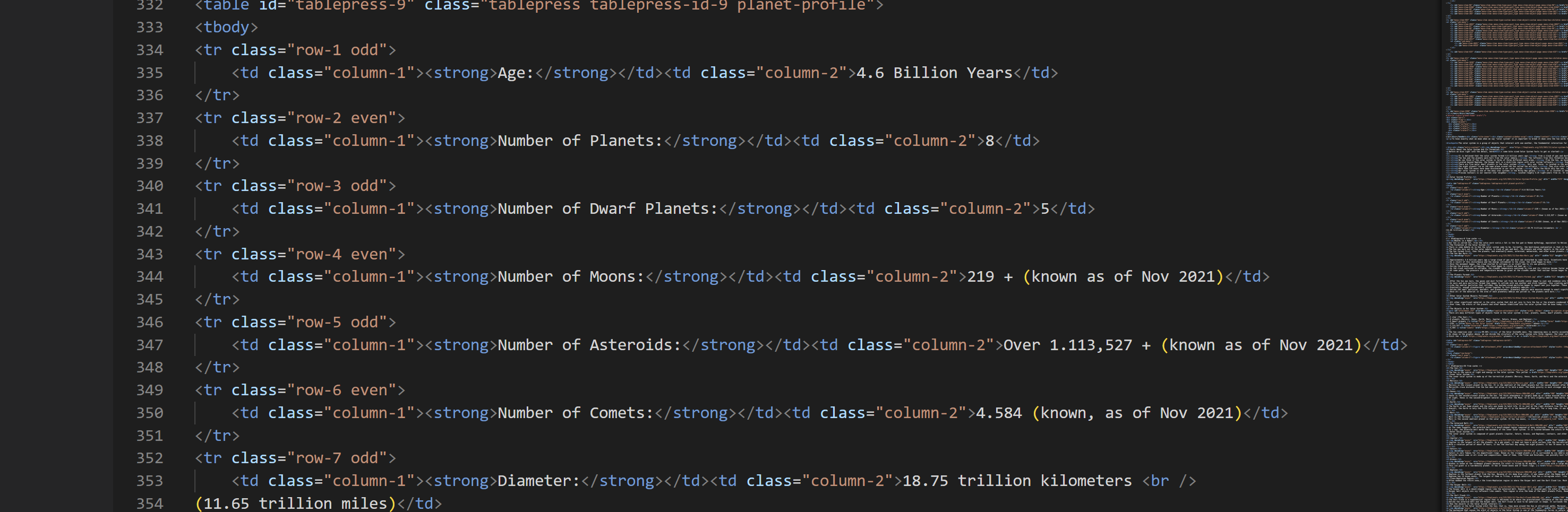
There are now 3 headers: Field1, DownloadData, DownloadHeaders. The data we need to extract from is in the DownloadData field.
3) To see the full string of data that has been downloaded, attached a browse tool to the download tool and run the workflow. Double clicking the DownloadData tool will open up a window above which expands what's within the cell and reveals the whole string.
4) The first 3 steps were the initial steps of web scraping, where we have extracted the data on the website as a string. Next, the key data wanted needs to be extracted out and cleaned so that there is a high quality table of data. This can be done in different ways on alteryx, depending on your preference or the way the data is organized. In this example I will mainly be using the RegEx tool. This can be joined to the download tool.
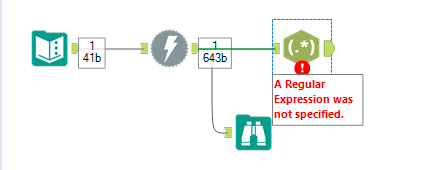
4) To set up the RegEx tool, check the configuration window to ensure it is correct. 'Column to parse' needs to be the field with the string of data, in this case, the DownloadData field.
5) Next, a regular expression needs to be made so the workflow knows what part of the string needs to be parsed. To go through the full string of data in a more clear fashion, Visual Studio Code can be used.

6) The string of data can be copied and pasted, from Alteryx to visual studio pro for analysis.
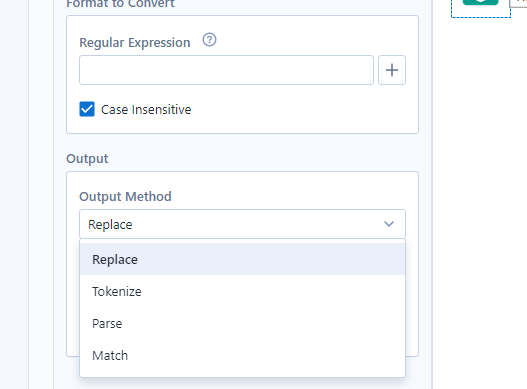
7) Once a RegEx expression is found it can be put into the Regular expression text box of the configuration window on Alteryx. With this tool you have multiple output methods that can be used, depending on what you would like to do.
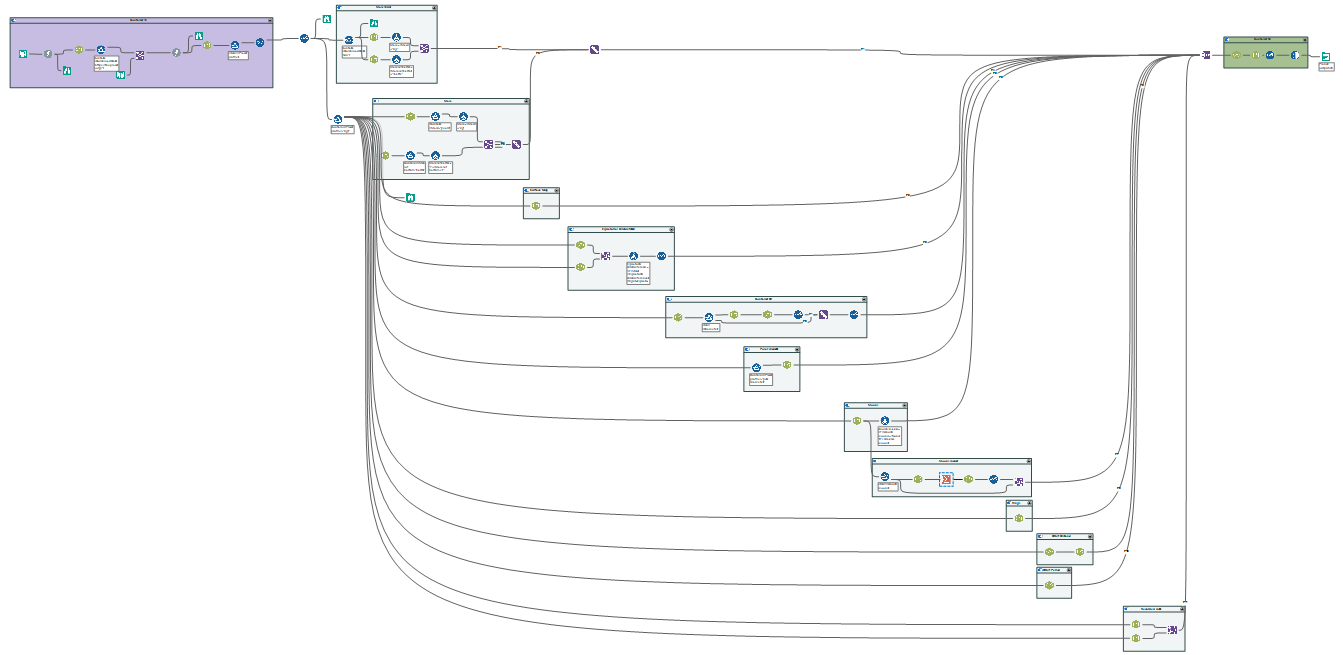
8) This webscrape had further URL links to download and scrape. Overall, muliple additional tools were used to ensure the data extracted would be outputted to a clean table. This tools included: filter, unique, join, select, formula, union, summarize. The overall workflow looked like this:
With the final output: