


Today we covered web scraping for the first time, and as usual I'm going to write a blog about it to be able to come back to it if I ever forget any of the steps.
I will be going through the steps I took on Alteryx to web scrape this website with multiple books and their prices: http://books.toscrape.com/catalogue/page-2.html
STEPS:
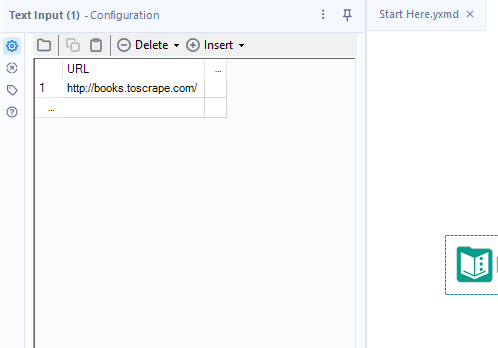
1)Copy URL: Copy the URL of the page you want to scrape into a text input tool like such:
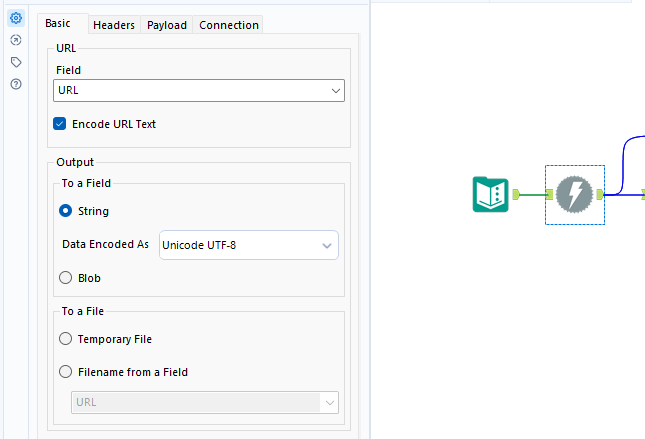
2)Download tool: Insert a download tool into your Alteryx workflow and configure in the following way:
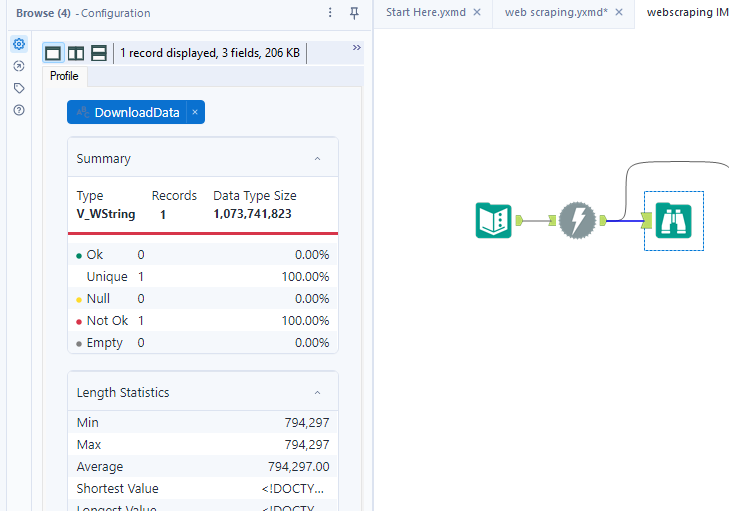
3)Add browse tool: Adding a browse tool will ensure you have all the data available to be copied in the following step.
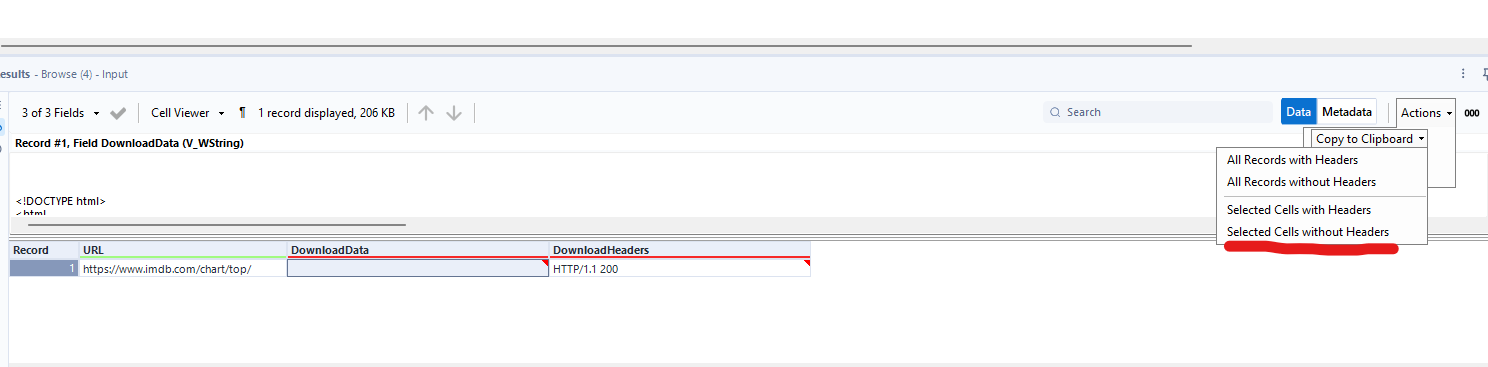
4)Copy download data without headers: click on the download data field in the results pane and go to action, copy in clipboard, and then selected cells without headers
5)Tokenize on delimiting section(<>) that separates areas with RegEx: Go on the website, right click and inspect. then look for a delimiter part that repeats itself for every section you want to pull the data from. In this example it was <h3>.

For this reason I configured the RegEx tool in the following manner:
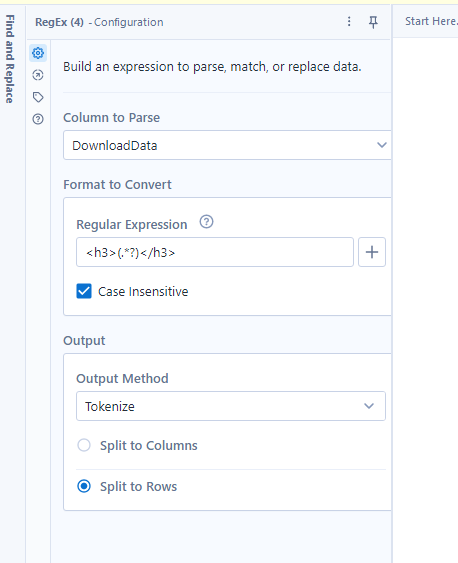
6) RegEx parse all info wanted : the way to do this is with copy, pasting and replacing wanted section with (.*?)
Here is how I used it to extract the price from the following text:
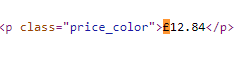
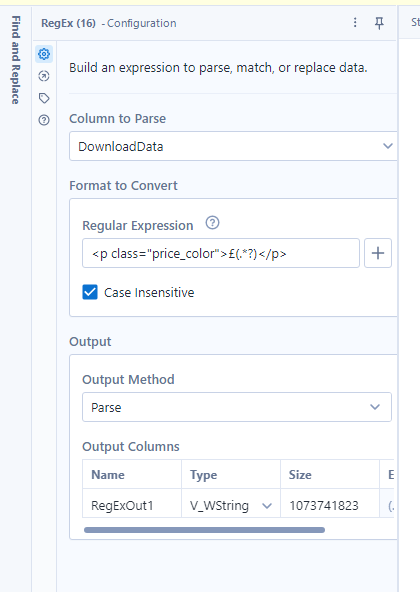
And another example for the rating:

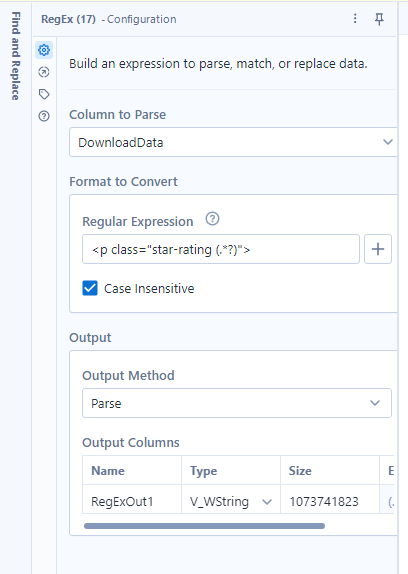
TIP: right click on the website and select inspect, then click on this icon and hover over the data on the website you want to find.
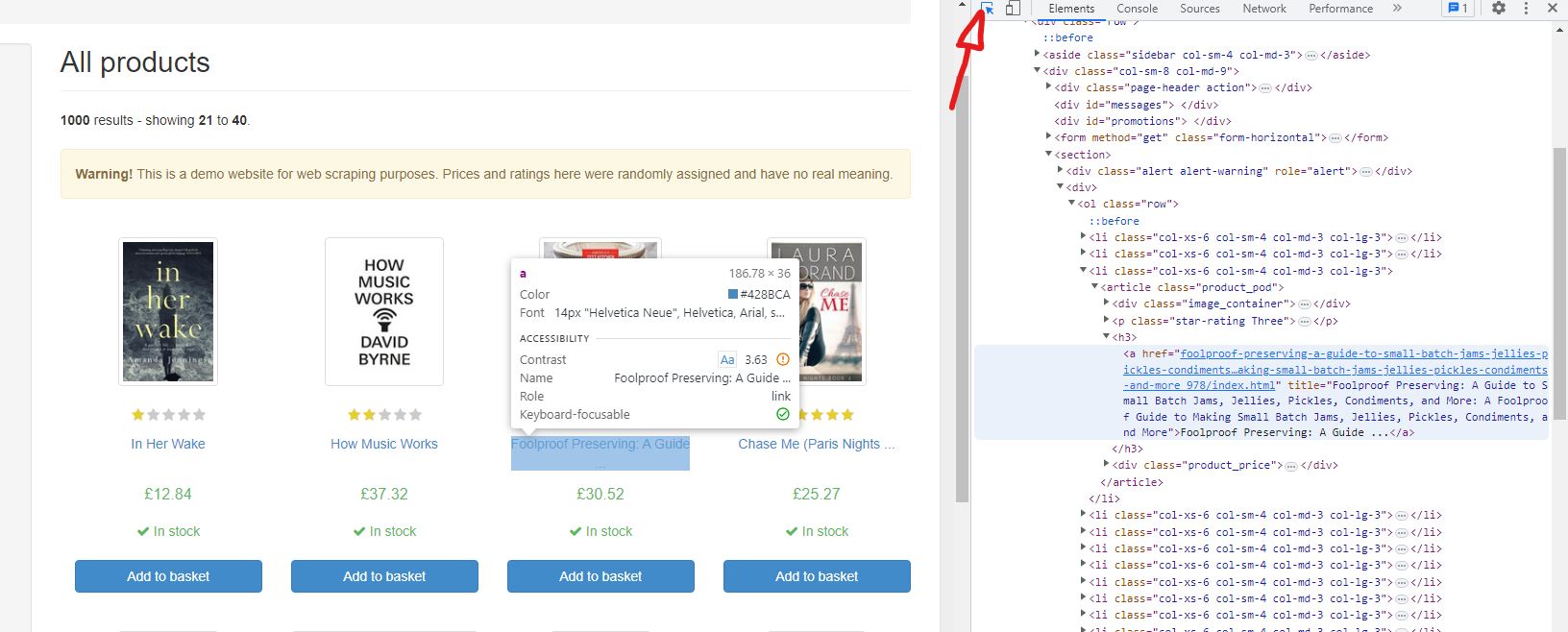
Then use ctrl+F on your keyboard and write what word you need for it to highlight and find it for you