


When talking about data, the cardinality of a column refers to the number of distinct values that the column can take on. A column with high cardinality has a large number of distinct values, while a column with low cardinality has a small number of distinct values.
For example, consider a table with a column called "gender" that can return either "male", "female", or "other". This column has a low cardinality, because it only has three distinct values but they are all appearing lots of times. On the other hand, consider a table with a column called "email" that stores the email address of each person in the table. This column has a high cardinality, because it can potentially have a large number of distinct values (one for each person in the table).
In general, columns with high cardinality tend to be more useful for identifying specific rows in a table, because the values in these columns are more unique. Low cardinality columns, on the other hand, are less useful for identifying specific rows, because the values in these columns are not as unique.
In another example imagine we have two datasets that we wan to connect with either a relationship or join, One table consists of a unique ID column and the name of a person, the other table also has an ID column and another field that has the sales for each person on different dates, but because each sales person has sales on different dates, the same ID appears multiple times.
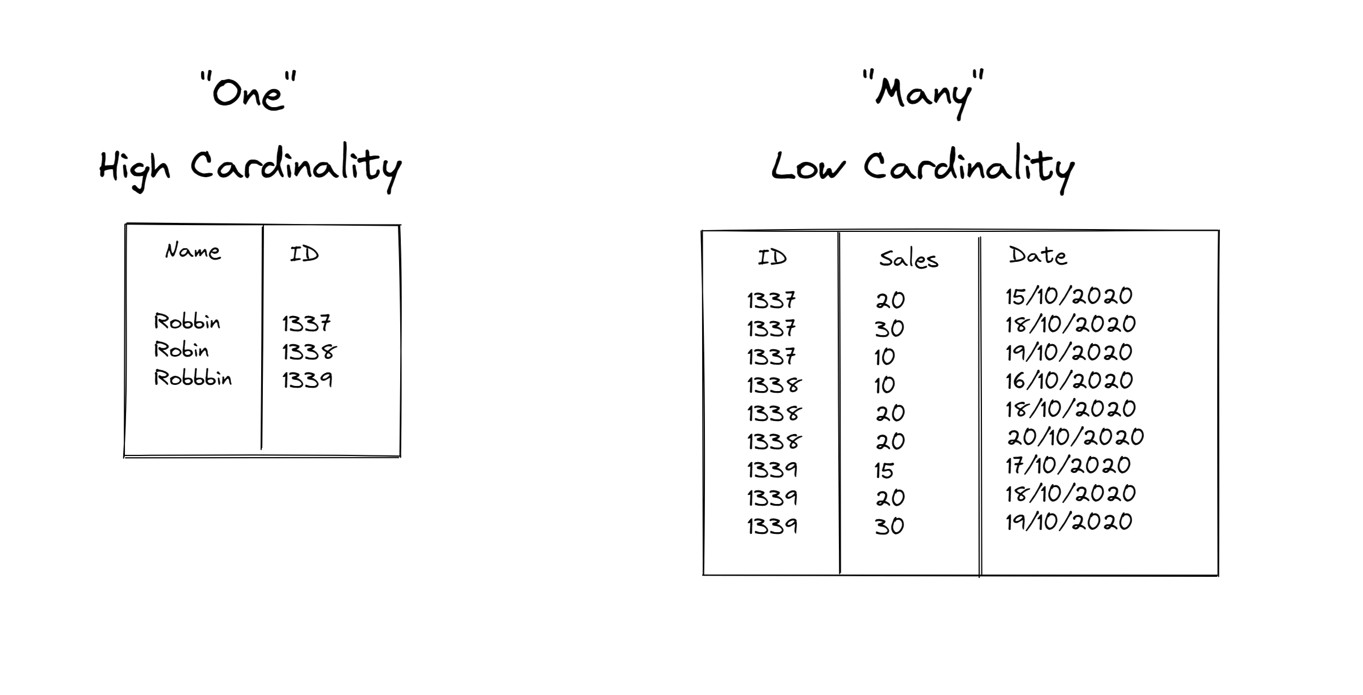
Because there are lots of repeated values (Many) the cardinality is low and because the first table has lots of distinct values (One) the cardinality is High.