


Pivoting a large number of columns is standard when analyzing survey data since surveys often store responses for each question in separate columns. Before analysis, the data needs to be reshaped, with question columns pivoted into rows to create a single column for questions and another for responses.
Now, imagine receiving survey data with over 200 questions, meaning just as many columns. Manually selecting and pivoting all those columns....You would probably think, "There has to be an easier way."—and yes, there is!
How to use Wildcards in Tableau Prep:
I'm using a survey data set from Kaggle, it has 482 columns with every question column named "Q" and a number.
1.Add a Pivot Step: Drag your dataset into the workflow and add a "Pivot" step.
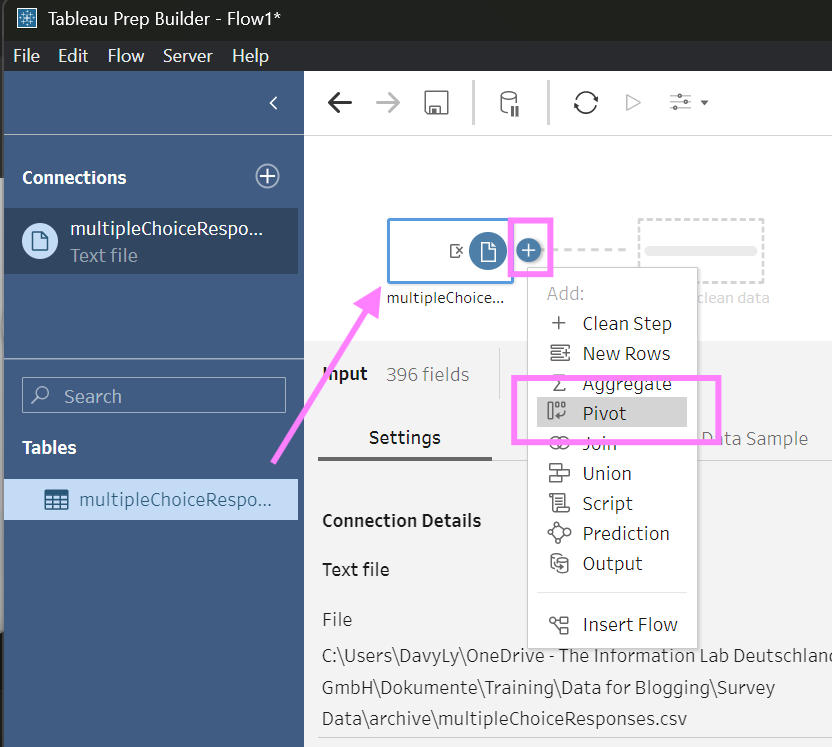
2.Switch to Wildcard Selection: In the pivot step, click on the "Use wildcard search to pivot"
3.Define Your Pattern: Enter a pattern such as "Starts with Q" to match all relevant columns.
4.Before and After Applying: Verify the matched columns and rename the new created question column.
Pros:
Wildcards save time and effort by reducing manual selection of individual columns, which also minimizes the risk of missing some or selecting the wrong ones. This is especially valuable when working with large datasets containing many columns. Additionally, wildcards make your workflow dynamic to future changes. When new question columns are added to a dataset, such as "Q567", they are automatically included in the wildcard selection. This dynamic power means you don’t have to revisit and manually adjust your pivot selections each time the dataset updates. Besides, even when you are no longer working on this data, you can still ensure a consistent data preparation process.
Cons:
Wildcards can sometimes include irrelevant columns that match the pattern but are not needed for the pivot. For example, a wildcard like Q* could include columns such as "Quarter" or "Quality" by mistake if they exist in the dataset. Additionally, wildcards rely on consistent naming patterns. If column names vary slightly, like "1Q" instead of "Q1," they might be excluded, resulting in incomplete data pivoting. This dependancy on consistency means their effectiveness is reduced when naming patterns are inconsistent. Moreover, selecting unintended columns like "Quarterly_Result" could lead to errors in your analysis, complicating the troubleshooting process. This is why I recommend to double check before applying the pivot step.
Conclusion:
Before diving into repetitive tasks like selecting specific columns for pivoting, where there’s a risk of missing some or selecting the wrong ones, take a moment and search for smarter solutions. Using wildcards is a perfect example of working smarter, not harder.