


Next up on the DSNY Channel is Kim Parse-able!
As mentioned in my blog post about passing the Alteryx Advanced exam, I completed only 4 challenges in preparation for the exam (#22, #36, #59, #211) (despite recommending many more in my blog post 😛). This blog post will go over #22 and #211, which I’m considering as basic. The official difficulty of #22 is Intermediate.
With real data that my cohort and I have worked on, it always helps to think about the final structure of the data in order for it to be visualized. With Alteryx Weekly Challenges, you always get to see the desired output, so you can focus on the process. Over time, doing these challenges have helped me get faster at the process and to get to the ideal data structure.
Challenge #22: Identify Values to Aggregate
We have ATM logs, and want to aggregate transaction amounts by row (which are the values right after "atm2.").

From examining the first few rows of the input, we can see that there’s an inconsistent number of transactions per row. I envision the final structure of the data to have each transaction amount in separate rows and then I can use a summarize tool. To ensure I am going to be aggregating the right transactions by row, I used the Record ID tool to give each row an ID.
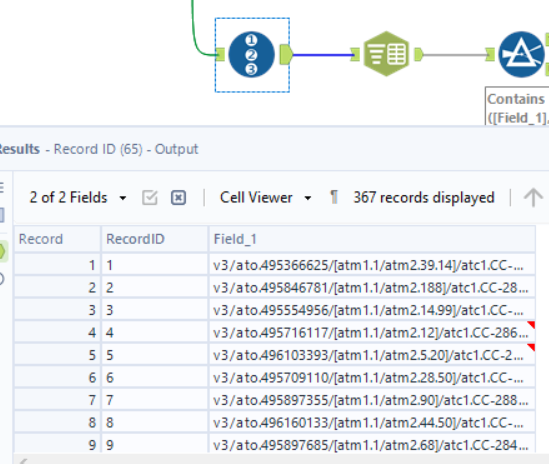
We can also see that sections of the string in Field_1 are separated by a slash “/”, so the next tool to use would be the Text to Columns tool, which does also Split to rows despite the name.

After splitting, we see that the correct RecordID is associated with everything from the first row. There are also many rows that are not relevant to us, but as we know transaction amounts are preceded by “atm2.”, we can filter for those rows only.
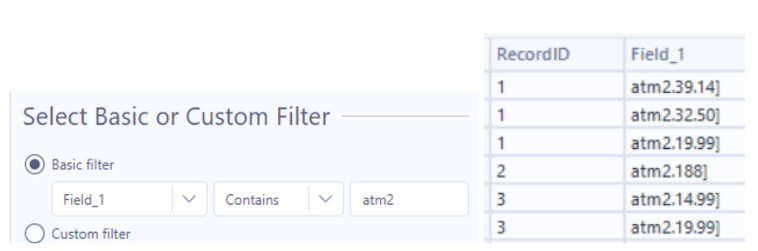
At this point, it’s clear how we need to clean these rows to only get the transaction amount - I used the RegEx tool.
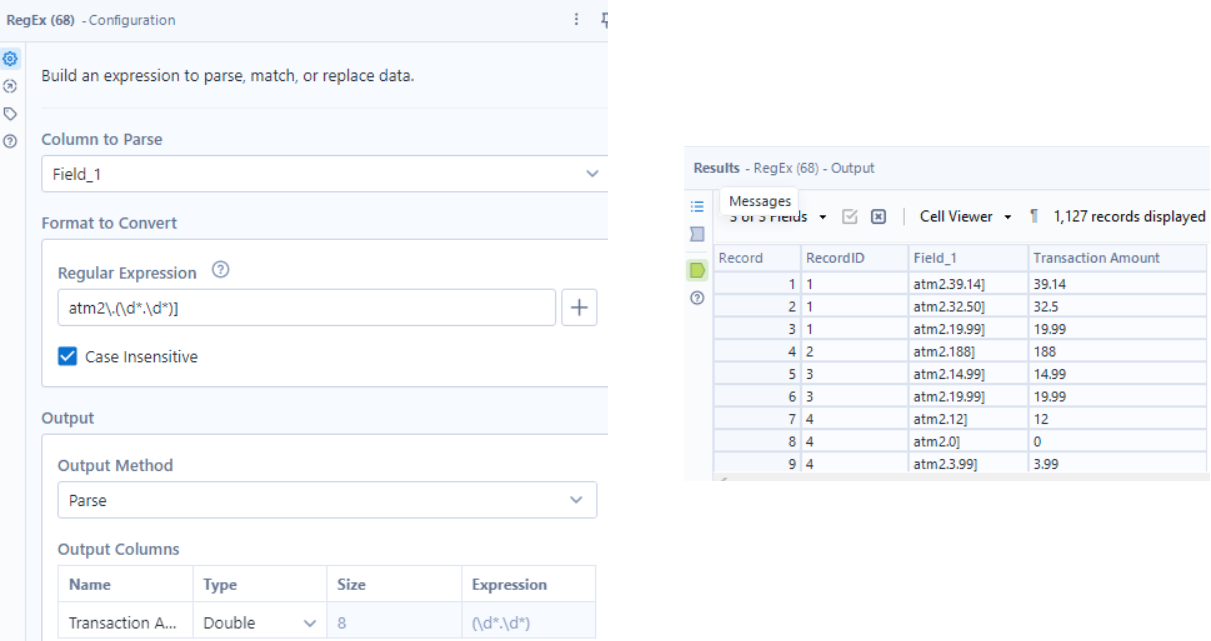
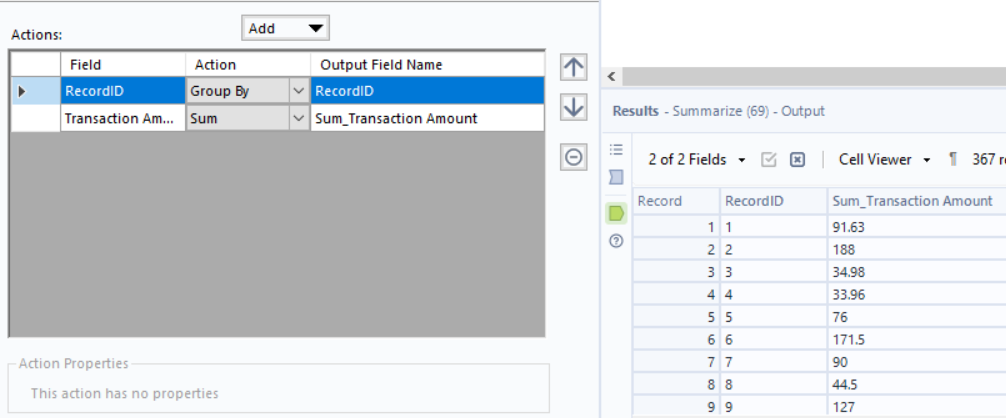
Lastly, I used a Summarize tool, and made sure to Group by RecordID.
Entire Workflow:

Challenge #211: Generating Email Addresses
The input for this challenge provides everyone’s name in a single cell of the table. Each name has a number after it, and we are to filter out any names without a number.

The delimiter here is a comma, so the Text to Columns tool works nicely; I split the Users field to rows so that each name is its own row.

I used the Formula and Filter tools to 1) determine if that row contained a number, then 2) filter to only names with a number. Turns out the only name without a number is “N/A”.

I used the RegEx tool to remove the number.

I used the Text to Columns tool next, with a space as the delimiter to get each component of a person’s name, then a Select tool to rename those columns for clarity.
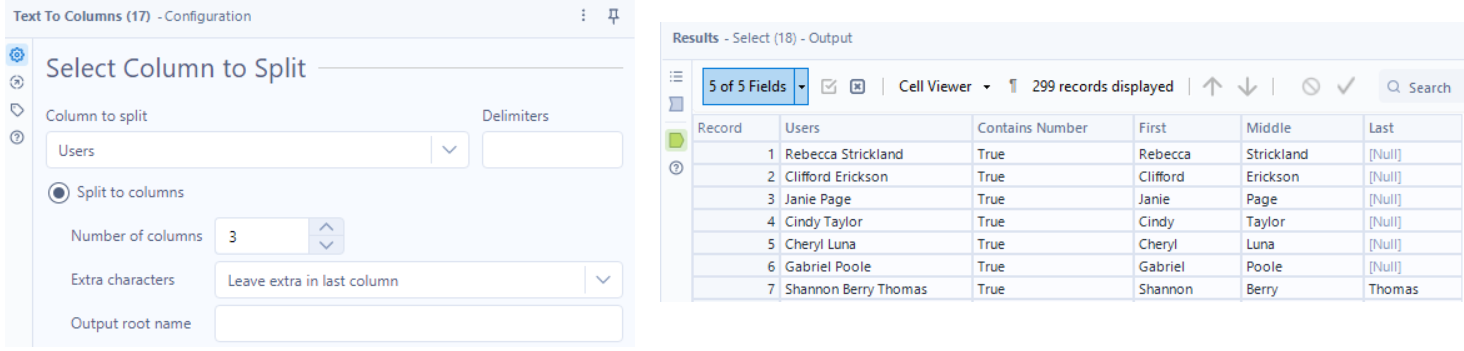
Many last names went to the Middle field as I set it to split to 3 columns. Using a Formula tool, I can pair up a first name with the “Middle” field, if and only if the “Last” field is NULL. With that, I can also build the Email field in the same Formula tool.
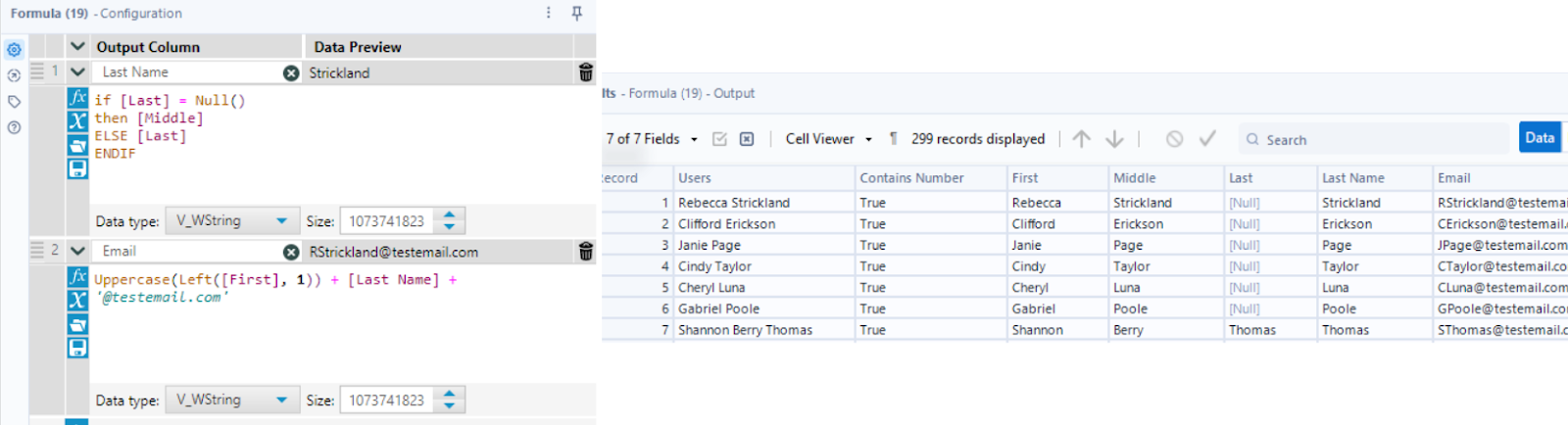
I used a Select tool to only leave the Users and Email fields remaining, then needed to determine the Email Group - which is the initial of their Emails. Note the Uppercase function I used in the above step - some of the names start with a lowercase letter, which will not be in the same email group.

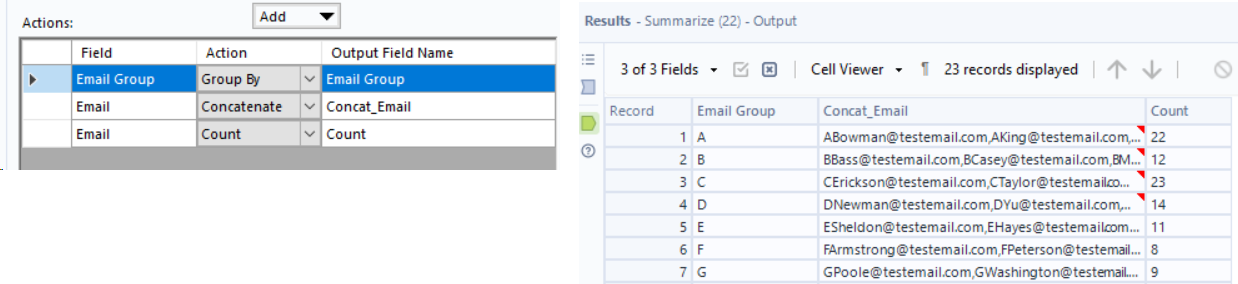
Lastly, I used a Summarize tool, grouping by Email Group to get the final output, and concatenating emails and counting the rows.
Entire Workflow:

Thanks for reading, next up will be intermediate challenges!