


This is the last blog post in which I cover Parsing & Data Prep Alteryx Challenges! Previous posts were on basic and intermediate challenges.
I'll be walking through my take on Challenge #188, a Difficult-level parsing and data preparation challenge. This challenge took me over 20 tools, but many solutions are under 10. I thought about this challenge in multiple parts: 1) getting the VAT No., 2) parsing out the detail lines, and 3) dynamically renaming the details with the right headers.
Challenge #188: Difficult, but not im-parse-able
We’re given an input of a single column and 185 rows that looks like a document:
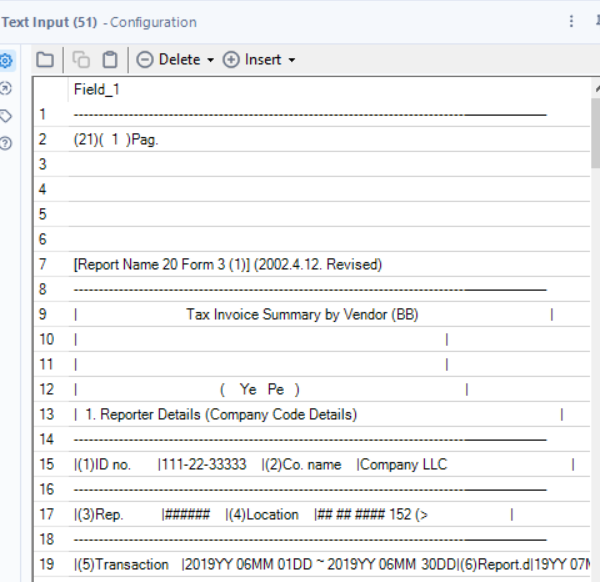
The Output has 8 columns, so the next step is to understand how the input is structured so that I can parse those fields out:
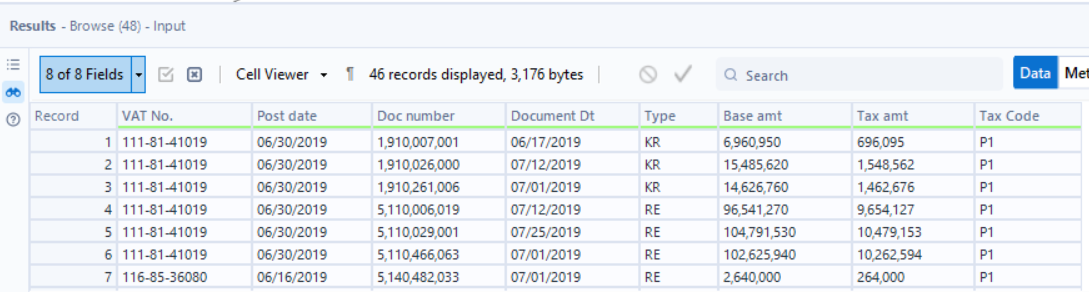
The first string of numbers, outlined in blue, is the VAT No. From looking through the data, I see that it’s always in this format, and there are 15 of them. The number preceding it (in this image, it’s 1) applies to the detail lines underneath it, until there is a new row with a new VAT No. (it would be preceded by a 2 next). This means that once I parse the detail lines out, I’ll need a Multi-Row Formula tool.
The second section outlined in blue are my other 7 fields - row headers then the values for the first VAT No. I noticed that every detail line has a date in it and that the date is always in a specific format.

Recognizing these two distinct patterns (VAT No. and dates) means that I can parse out only these columns with RegEx. The first row has headers and an example VAT No., so I used the Select Records tool to exclude it.
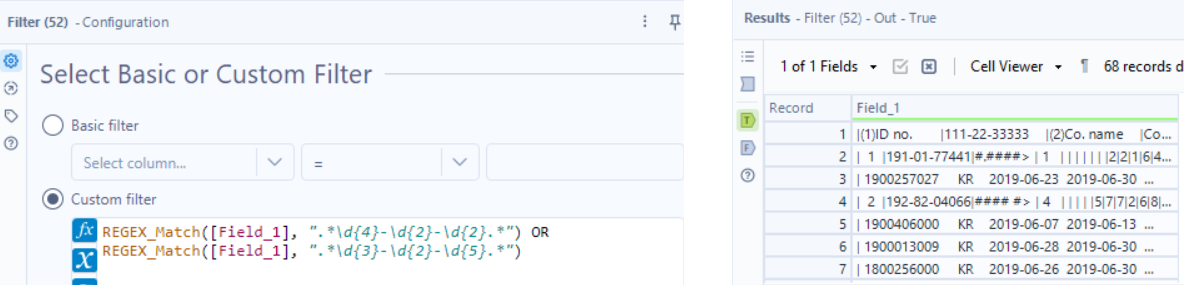
The next step is to parse out the VAT No.; these rows use pipes to separate different data. The pattern of the VAT No. is 3 numbers, then 2 numbers, then 5 numbers; in RegEx that would be: \d{3}-\d{2}-\d{5}. Since the detail lines don’t have pipes in them, the new VAT No. column will be null.

Those detail lines need to be associated with a VAT No. above it, so I’ll use a Multi-Row Formula tool.

I still have the VAT No. rows and detail lines mixed in together, but part of the challenge is to filter to rows that only have a tax code of P1 or P9. VAT No. rows do not have a tax code and will get filtered out later.
So next I want to work on parsing out information for the detail lines. Each field is separated by multiple spaces, so if I want to parse on a space, I would get a lot of null columns. Instead, I’ll use RegEx to replace multiple spaces with a pipe. Now we can easily see how to use the Text to Columns tool.

Given the extra pipes, I separated the [2] field into 10 columns.
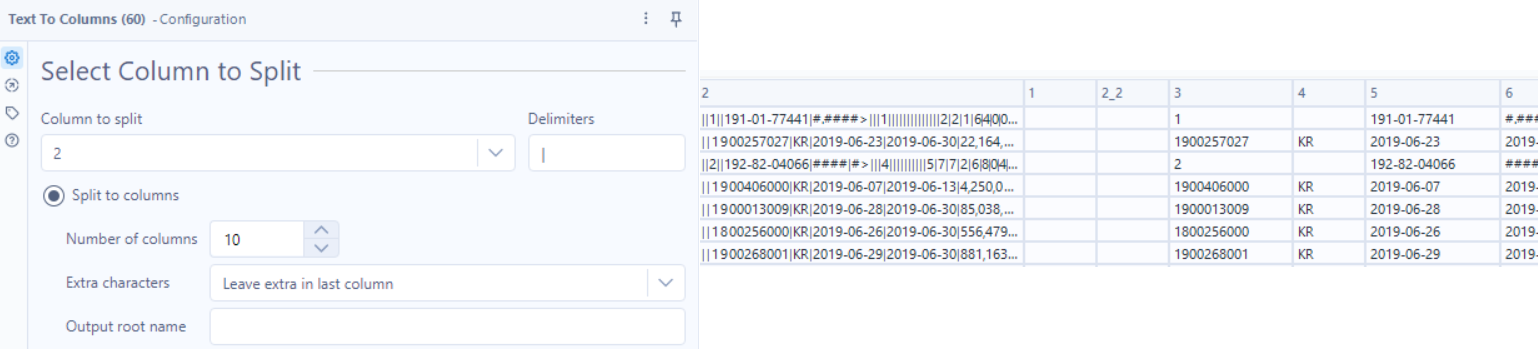
I used a Select tool to remove all rows but the 8 in the final output.

Now, I’m going to diverge from this workflow, and use the input again to dynamically get the headers for these fields. From the input, I used a Filter tool to get rows with “Doc” in them, as those headers are repeated throughout the data. Like the detail lines, each header is separated by multiple spaces, so I’ll use RegEx_Replace again to make the spaces into pipes.
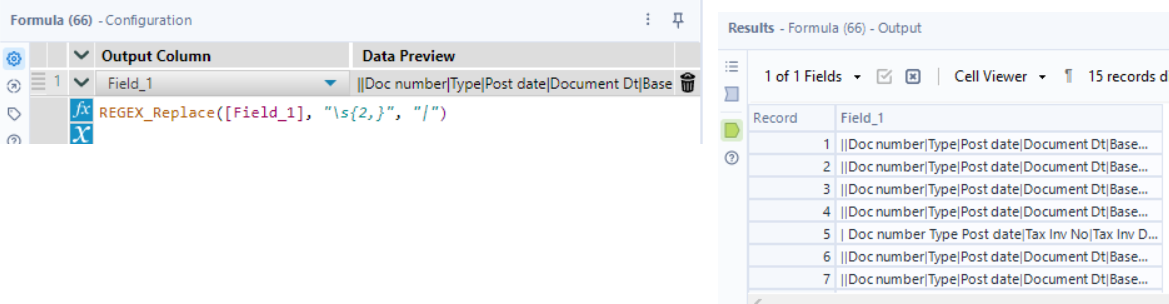
I removed unnecessary columns, and selected only the first record. I’ll be transposing this data with no key columns and then using the Dynamic Rename tool, so at this stage I checked that my detail table fields were in the same order.
This section can be much shorter by using a Text Input tool and inputting the headers in a single field.

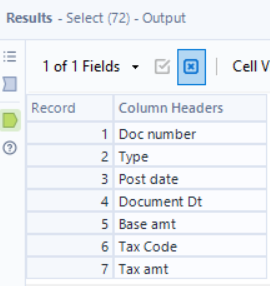
Now I’ll connect my details table (L anchor) with the headers (R anchor) in the Dynamic Rename tool.
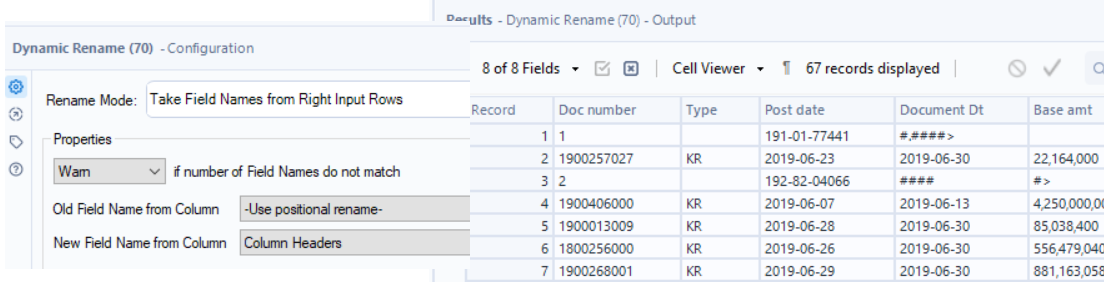
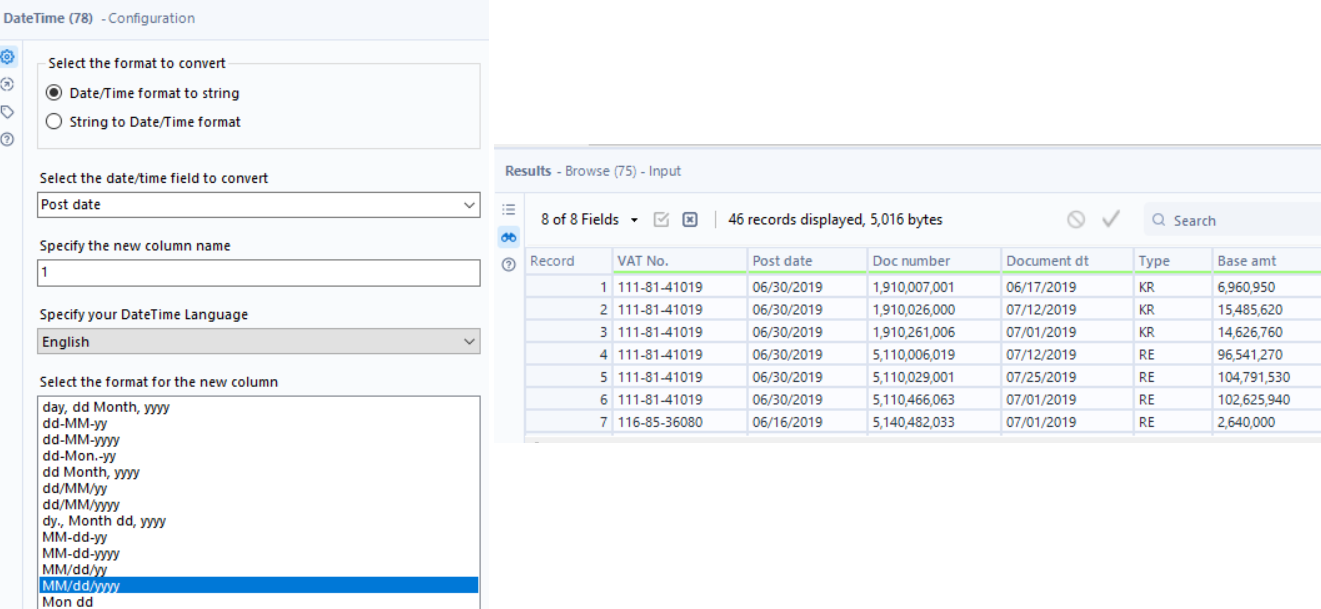
At this point, I filtered for the tax codes and ended up with 46 records, the same as the output. With a Select tool, I changed Post date and Document Dt to date types - this can be done earlier, but I decided to do it after the Dynamic Rename. I also sorted the VAT No. by Ascending order to match the output.
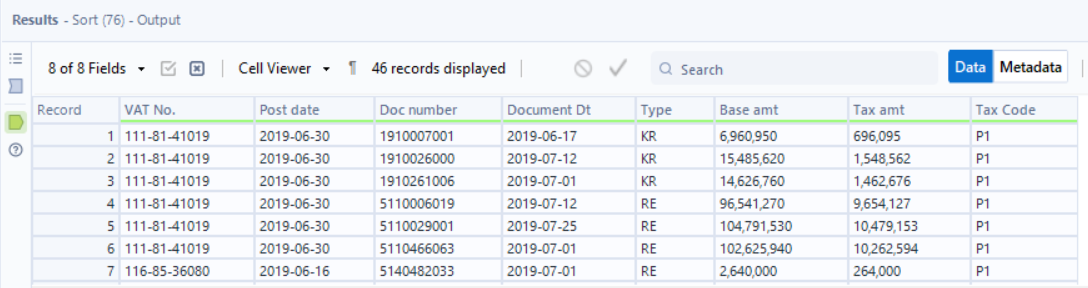
We’re very close, we just need to change the date format to use slashes instead. I used two DateTime tools for the two dates, then finally a select tool to remove the original date columns and reorder them. Voila!
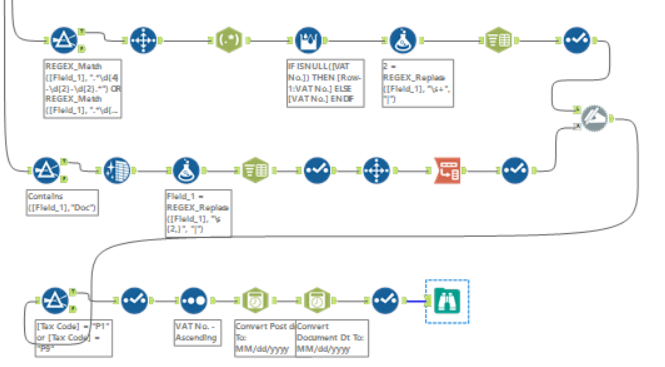
Entire Workflow:
Thank you for reading! Mission Im-parse-able accomplished 😎