


I started with writing about basic challenges in my previous blog post; this post will focus on intermediate parsing & data prep Alteryx challenges: #36 and #59.
These are both Intermediate challenges.
Challenge #36: Data Cleansing Extract Authors
The input file is a single column with lots of different kinds of information within it, specifically details about medical journal publications.

The objective is to parse out the PMID, and every author of that publication in a single row. The output should look like:

I started this challenge with a formula tool to clean up the PMID and FAU rows, and create a flag to keep or remove a row. As the rows for PMID and Author always have the same prefix, we can clean them by trimming the first 5 or 6 characters across the entire table.


As per the instructions, we only need the PMID and FAU rows, so if the original field contains that prefix, the Keep Columns field will evaluate to True.

After a Filter tool, it’s clear that the PMID column needs to be filled down to associate the right PMID with the right authors.

In Alteryx, we use the Multi-Row Formula tool to fill down. If the PMID is null for that row, we want to pull it from the row above.
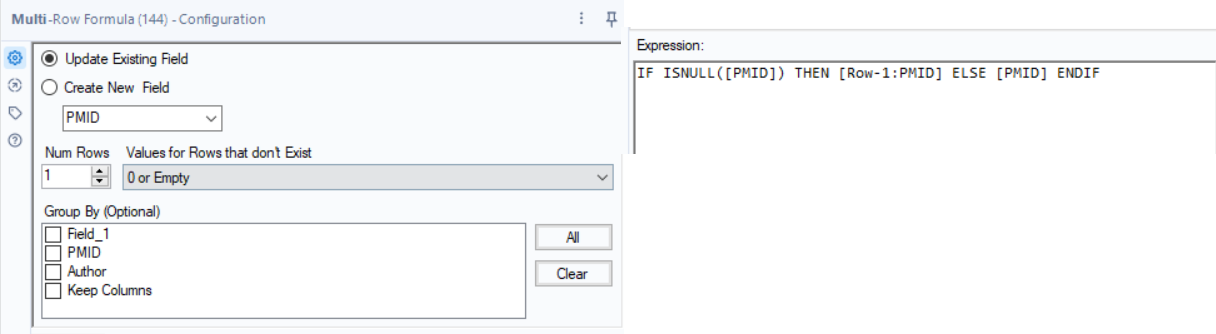
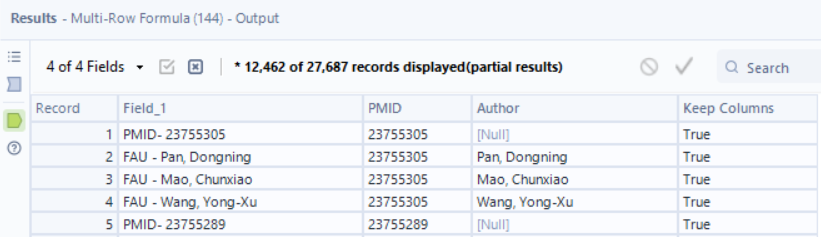
The rows where Field_1 is only the PMID don’t have an author and can be removed now that we’ve gotten the information we needed. With a filter and select tool to get rid of unneeded columns, we then have a tall and skinny table where each row is a different author. I also sorted at this stage to compare my in-progress results with the output.
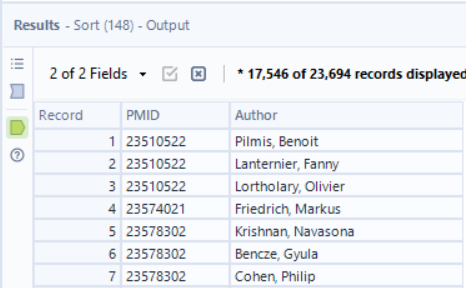
A pivot from rows to columns is needed to get authors on the same row, and one handy way to do it is with a Summarize tool. With strings, the aggregation method is Concatenation, with a pipe (“|”) as the separator. (Any separator can be used, but best to avoid any character that is already within author names, like the comma.)

After this, the Text to Columns tool can be used to separate the authors - however it does require we know how many columns to separate. I diverged from my main workflow to find the answer by counting the number of pipes in the row. Adding 1 to that number will be the total number of authors in the Concat_Author field.

By sorting the “count separators” field, I discovered the most authors for a journal was 264, so that’s what I used in the Text to Columns configuration.

I used a select tool to remove the Concat_Author field, and voila!

Entire Workflow:

Challenge #59: Is it an Anagram?
The goal of this challenge is to determine if the words in the same row are anagrams of each other. Left - the input, right - the desired output. Seeing the RecordID in the output is a good hint that the Record ID tool is needed.
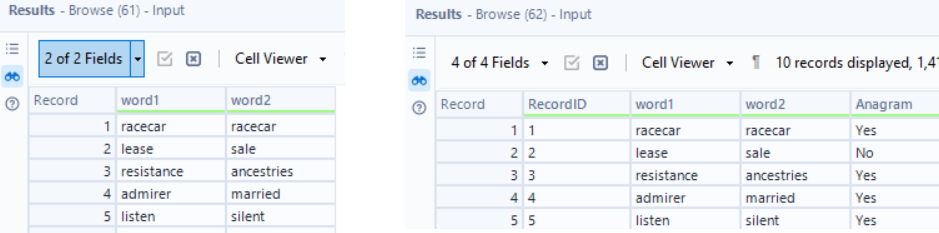
The way I approached this problem was to separate each letter of each word into individual letters, sort the letters in each word alphabetically, then compare them. The way to do that is to restructure the data, pull it apart, put it back together, and ensure that the right letters are associated with the right word.
My first step was to give each row, a pair of words, a RecordID, then transpose the data. This means that one column contains each word, while another column tells you if it was from word1 or word2; the record ID is then what tells you which two words are paired together.

Next, I want to split the word by each letter, which is not something you can do in the typical Text to Columns tool, as it needs a delimiter, and that is different for each word and position within the word - which means we need RegEx. I split to rows on the wildcard character (“.”) to get each letter of each word on its own row.
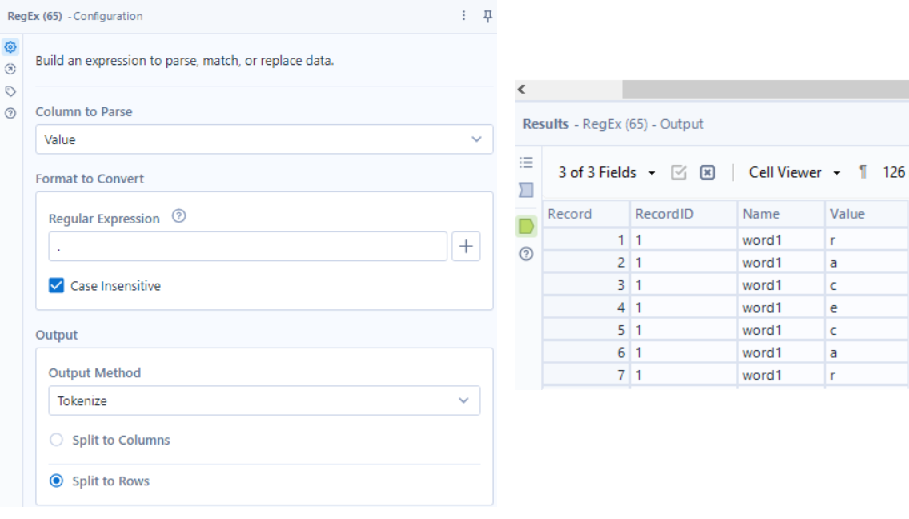
I sorted each word’s letters alphabetically:

Now all I need to do is concatenate, and see if word1 = word2 - if it does, it’s an anagram. I concatenated using the Cross Tab tool, grouping by the record ID (which keeps the pairing of the words).
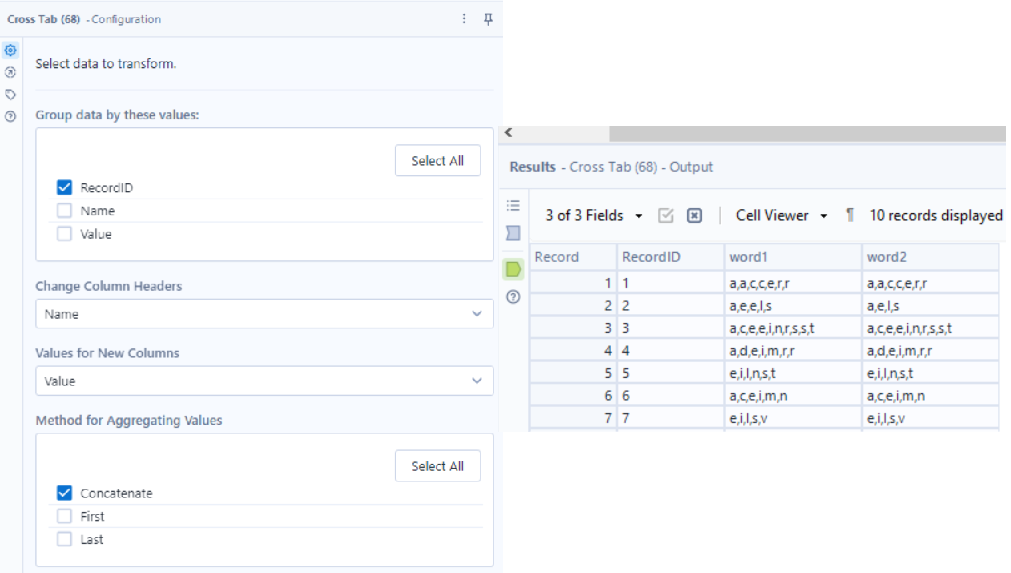
I cleaned the commas out of the words (which isn’t necessary) and used a formula tool to create the Anagram field.

The last step is to get the original words back, which makes the Record ID handy as I can simply join this last result with the table from the first step, when we first assigned a Record ID.
Entire Workflow:

Thanks for reading!