


What does it mean when data is normalized or denormalized?
Let's break down the difference using an example of a simple database for a fictional store.
Normalized Data Example:
Suppose we have the following tables in a normalized database:
Customers Table:

Orders Table:
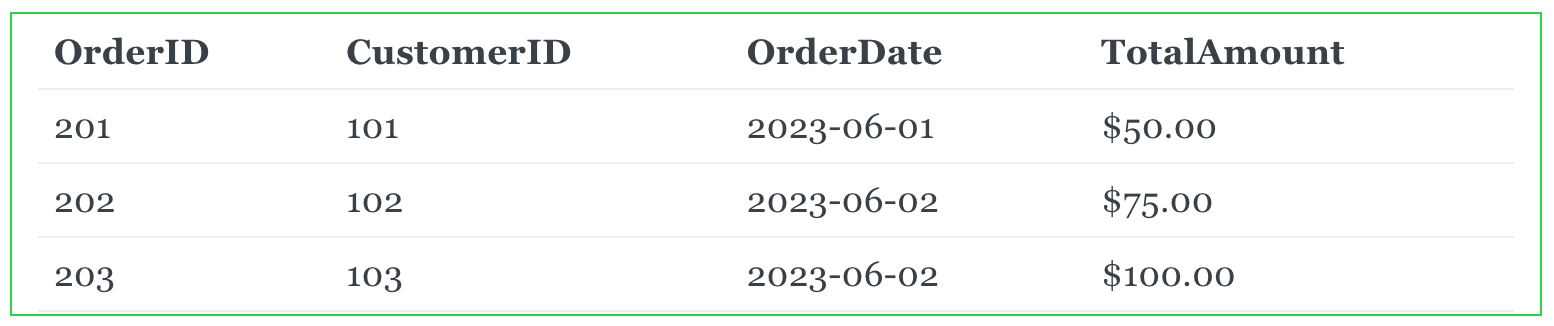
In this normalized database:
- Customer information (CustomerID, Name, Email, Address) is stored in the "Customers" table, where each customer has a unique identifier, which is the CustomerID.
- Order information (OrderID, CustomerID, OrderDate, TotalAmount) is stored in the "Orders" table, with the column CustomerID as a foreign key linking each order to the respective customer in the "Customers" table.
Advantages of Normalized Data:
- Data redundancy is minimized. Customer information is stored only once, even if a customer has multiple orders.
- Data integrity, ie the accuracy, consistency, and reliability of the data is maintained, as each piece of information is stored in a single place.
- Easier to update and manage data. If customer details change (e.g. a customer moves to a new address), it only needs to be updated in one location.
Disadvantage of Normalized Data:
• Required Development: Designing and maintaining a properly normalized database may require more upfront planning and design efforts compared to denormalized data structures.
Denormalized Data Example:
Now, let's take a look at a denormalized version of the same database, where some information is duplicated across tables:
Customers Table:

Orders Table (Denormalized):

In this denormalized database:
- Some customer information (Name, Email, Address) is duplicated in the "Orders" table along with the order information.
- CustomerID is not used in the "Orders" table since customer information is directly stored in the same table.
Note: Not having a unique identifier across multiple tables can cause issues if the database is more complex since not having an unique identifier will not allow the data to be joined in a reliable way; It might require a more complex and multi-table joins compared to normalized data, as related information might be spread across multiple redundant copies.
Advantage of Denormalized Data:
- Simplified query performance: Since customer information is already available in the "Orders" table, there is no need for additional joins to retrieve customer details when querying order information.
- Improved reporting efficiency: Reports that require both order and customer details can be generated faster, as all information is present in one table.
Disadvantage of Denormalized Data
• Data Maintenance Issues: Updating and maintaining denormalized data can be more complex, as changes need to be made in multiple locations. This can increase the chances of update anomalies and data inconsistencies if not handled carefully.
In Summary,
Normalized data minimizes data redundancy and ensures data integrity, but it may require more queries with joins to retrieve related information. Denormalized data, on the other hand, may improve query performance and reporting efficiency but can lead to data redundancy, difficulty querying with joins to retrieve more related information and potential data integrity issues if not carefully managed.