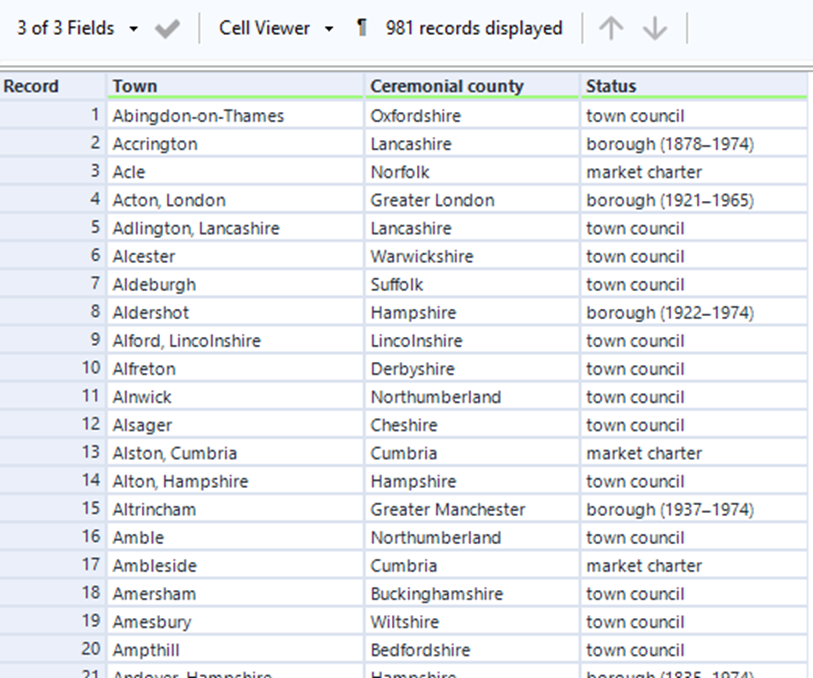
Web Scraping can be an effective way to pull much data from an internet source and Alteryx is very helpful at doing so. Here I want to share with you how you can quickly get publicly available data from a website and transform it to make it useable.
There are some legal issues associated with web scraping data, especially when it comes to personal data, this will not be covered in this post, but it is something you should be aware of.
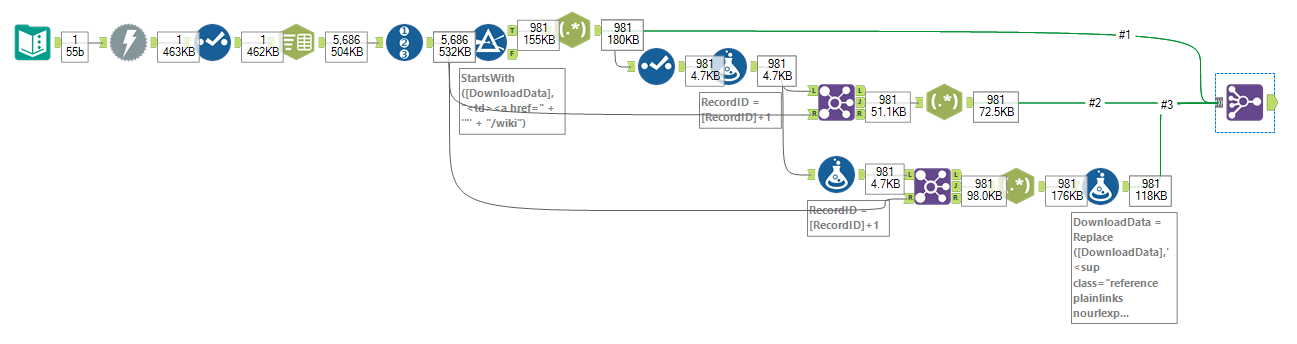
With a short workflow, like the one shown below, you can pull big amounts of data from a web source, even if it does not offer API access.
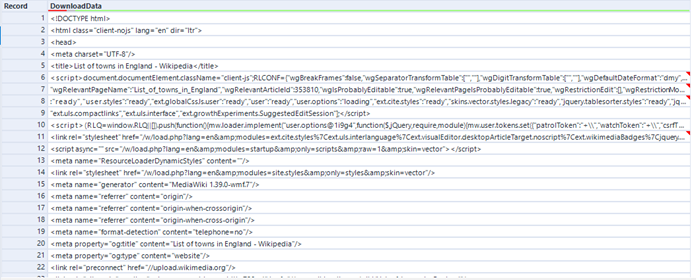
So let’s go through this together. I have selected a Wikipedia article of interest about towns in England, containing a table with three different columns we want to download. We can use a Text Input Tool to input the URL of the article into our Download Tool. The Tool will then download the HTML code of the webpage into a single cell. We can see in Fig.2 that Alteryx only shows us the first few lines of the downloaded data.

To show us all the data, we can split the data into multiple rows, using a Text To Column Tool, by each line break (\n).
At this point, you might need to get a bit creative. Based on how the web page’s code looks, you have to take a different approach. To find out how you can best access the information you want, you should always take a look at the Webpage’s source code (Control + U in the Browser). Here you can try to find a pattern that lets you extract the data.
When we compare the Wikipedia table and the page’s source code, we can see the pattern here (Fig. 4)

Once you understand how the HTML code is built, you can use Filters, RegEx, and other simple data transformation tools, to get the data in the desired form.
In Fig. 5 you can see the steps to get the town names out of the code page.
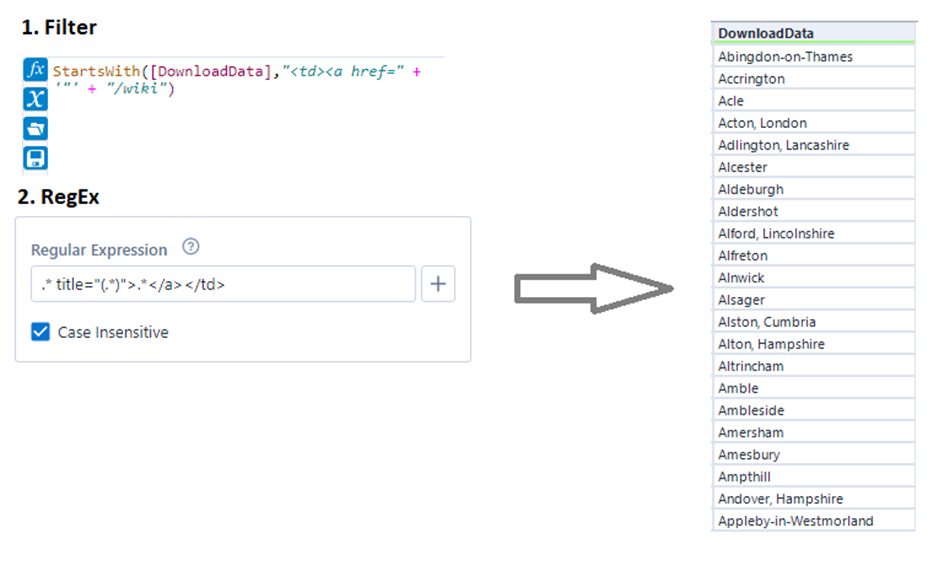
That’s the first column we wanted to get. Since the data in the two other columns can be found in the HTML code one and two lines below the town names, using Record ID Tools is an easy way to extract this information, without the need to filter it down to something again.
Therefore the Record ID is increased by one, and the data behind this data is obtained using a Join Tool. The same step is completed once more for the third column. After transforming them using RegEx they can be joined on the record position, this process is shown in Fig. 1.
It is important to make sure that you got the same number of results at every step, otherwise, this won’t work and you would get the wrong results.
Once you have completed this and done some quick renaming, you end up with the same table, as is shown on Wikipedia (Fig. 6).